Der Begriff kolorektal bezieht sich auf die Kombination aus Kolon (Dickdarm) und Rektum, die beide Bestandteile des Verdauungssystems sind. Der Dickdarm absorbiert Wasser und Elektrolyte aus der verdauten Nahrung, während das Rektum als unterster Teil des Dickdarms fungiert und zum Anus führt. Die kolorektale Gesundheit ist entscheidend für die Verdauung und die Ausscheidung von Abfallstoffen. Kolorektalkrebs ist eine Krebsart, die im Dickdarm oder Rektum beginnt, die zusammen als kolorektaler Bereich bezeichnet werden.
Kolorektalkrebs ist der dritthäufigste Krebs weltweit und die viertführende Todesursache. Er beginnt mit gutartigen Polypen in der Schleimhaut des Dickdarms oder Rektums, die sich im Laufe der Zeit zu bösartigen Tumoren entwickeln können.
Risikofaktoren umfassen
- Fettleibigkeit
- Eine Ernährung mit wenig Obst und Gemüse
- Körperliche Inaktivität
- Rauchen
Behandlungsoptionen umfassen Operation, Chemotherapie, Strahlentherapie, gezielte Therapie oder eine Kombination davon. Vorbeugende Maßnahmen umfassen einen gesunden Lebensstil, Bewegung, Gewichtsmanagement und frühzeitige medizinische Eingriffe.

KI unterstützt maßgeblich verschiedene Aspekte der kolorektalen Krebsversorgung, einschließlich der Früherkennung, der personalisierten Behandlungsplanung, der Prognosevorhersagen und der Arzneimittelforschung. Sie verbessert die Analyse medizinischer Bildgebung, die Risikobewertung und die Auswertung von Patientendaten. Durch die Optimierung von Prozessen und das Bereitstellen von Einblicken trägt KI zu verbesserten Ergebnissen im Management von kolorektalem Krebs bei.
HSA KIT
Die HSA KIT-Software bietet eine intuitive Benutzeroberfläche und erweiterte Annotationsfunktionen für präzise Details bis hin zu einzelnen Pixeln. Sie verbessert die Analyse, indem sie Prozesse standardisiert, Konsistenz aufrechterhält und Reproduzierbarkeit ermöglicht.
Das HyperCRC-Net-Modul in HSA KIT klassifiziert das Basis-ROI (Region of Interest) äußerst effektiv in verschiedene Drüsenarten:
- Gesundes Gewebe
- Adenom
- Karzinom
- Andere Gewebe (Muskel, Fett oder Stroma)
Im Kontext von kolorektalem Krebs:
- Gesund – Gesundes Gewebe: Bezieht sich auf normales, nicht krebsartiges Gewebe im Dickdarm oder Rektum.
- Adenom: Ein präkanzeröses Wachstum oder Tumor, der sich in der Schleimhaut des Dickdarms oder Rektums entwickeln kann. Es hat das Potenzial, sich im Laufe der Zeit zu Krebs zu entwickeln.
- Karzinom: Krebs, der von Epithelzellen im Dickdarm oder Rektum ausgeht. Er kann in nahegelegenes Gewebe eindringen und sich möglicherweise auf andere Teile des Körpers ausbreiten.
Diese Begriffe helfen, zwischen gesundem Gewebe, präkanzerösen Wucherungen und krebsartigen Tumoren bei kolorektalen Krebsfällen zu unterscheiden.


Ein Bild der Erkennung von gesundem Gewebe und Adenom


Ein Beispiel für die Erkennung von Karzinom und Adenom.


Ansicht im Überblick: Viele gesunde Drüsen wurden gefunden.


Zoom-Ansicht: Viele gesunde Drüsen wurden gefunden.


Ansicht im Überblick: Zahlreiche Adenome erkannt.


Zoom-Ansicht: Zahlreiche Adenome erkannt.


Ansicht im Überblick: Zahlreiche Karzinome erkannt.


Zoom-Ansicht: Zahlreiche Karzinome erkannt.
Färbung und Marker
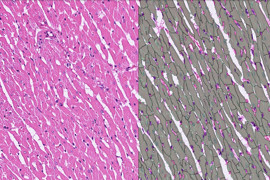
HE (Hämatoxylin und Eosin) Färbung ist eine entscheidende histologische Technik in der Pathologie. Durch das Hervorheben von zellulären Elementen hilft sie Pathologen bei der Beurteilung von kolorektalem Krebs anhand von Biopsieproben. Der Prozess umfasst das Färben von Gewebeschnitten mit Hämatoxylin für Zellkerne und Eosin für Zytoplasma und Matrix, was die Analyse von Gewebeeigenschaften und -architektur ermöglicht. Dies unterstützt bei der Erkennung, Bewertung und Behandlungsplanung für Patienten mit kolorektalem Krebs.
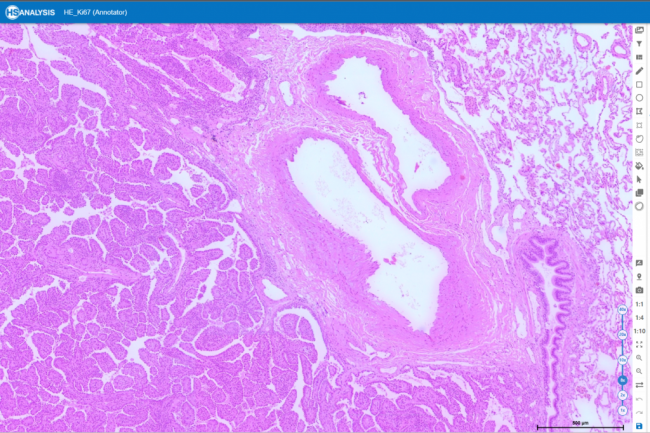
Ki-67 Färbung ist eine immunhistochemische Methode, die die Expression des Ki-67-Proteins in Zellen identifiziert, was auf Zellproliferation hinweist. Es ist entscheidend in der Krebsforschung, zur Prognosevorhersage und zur Bewertung der Behandlung. Unter dem Mikroskop zeigt es die Anwesenheit von Ki-67-Protein, was bei der Bewertung von Zellproliferationsraten und der Identifizierung von teilenden Zellen hilft. Es ist besonders nützlich bei der Unterscheidung von Tumoren von anderen Wucherungen und der Bewertung des Risikos einer Krankheitsverschlimmerung.
Das HSA KIT bietet einen ganzheitlichen Ansatz zur Erkennung von kolorektalem Krebs aus histopathologischen Schnitten. Es nutzt verschiedene Färbungen und annotierte Datensätze, um das HyperCRC-Net-Modul zu trainieren, das die Merkmale von kolorektalem Krebs hervorhebt. Details wie Zellstruktur, Muster und Ki-67-Expression werden für präzise Vorhersagen gesammelt. Die Erkennung, Segmentierung, Klassifizierung und Bewertung von kolorektalem Krebs basiert auf histologischen Merkmalen, der Ki-67-Expression und Proliferationsraten. Darüber hinaus liefert es prognostische Informationen für Patientenergebnisse und Behandlungsentscheidungen.Beim Analysieren histopathologischer Schnitte bietet das HSA KIT eine umfassende Split-Screen-Lösung zur Erkennung von kolorektalem Krebs mithilfe mehrerer Färbungen. Für die Diagnose können Sie einfach zwei oder mehr digitale Schnitte in der Splitscreen-Funktion öffnen und die Umgebung des Ki-67-Schnitts und die gleiche Position des HE-Schnitts überprüfen.
Sie können nur in einen Schnitt hineinzoomen und der zweite Schnitt wird den gleichen Zoom-Level und die gleiche Position ändern. Auf diese Weise können Sie einfach für die Diagnose zwei Färbungen vergleichen.



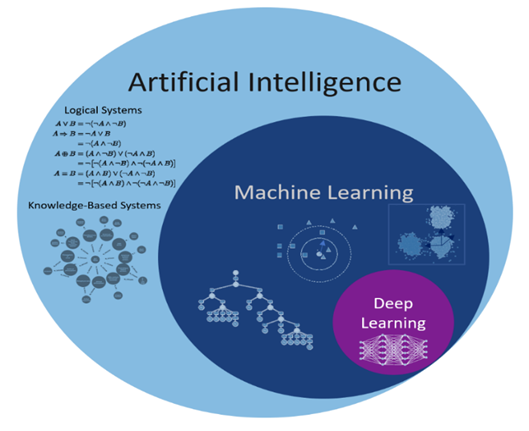
Deep Learning (DL)
Die Verbindung zwischen Deep Learning, maschinellem Lernen und KI. Künstliche Intelligenz (KI) bezieht sich auf Techniken, die es Computern ermöglichen, menschliches Verhalten zu imitieren. Mithilfe von Algorithmen, die auf Daten trainiert wurden, ermöglicht maschinelles Lernen Computern, Dinge zu klassifizieren oder vorherzusagen. Deep Learning ist eine Form des maschinellen Lernens, bei der Daten analysiert und Muster mithilfe mehrschichtiger neuronaler Netze erkannt werden, ähnlich wie beim menschlichen Gehirn. Die Struktur des menschlichen Gehirns diente als Inspiration für die Architektur des neuronalen Netzes.
Ground Truth Data (GTD)
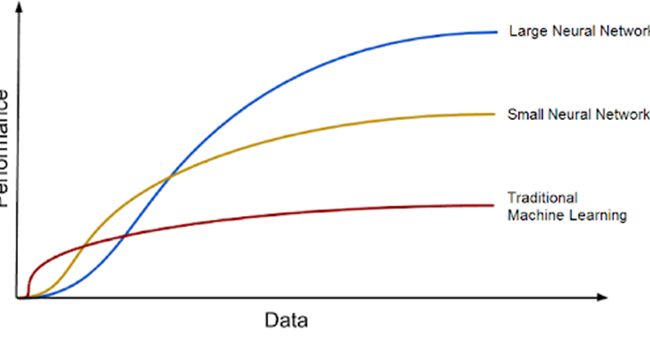
GTD bezieht sich auf die tatsächliche Art des Problems, mit dem sich ein Modell für maschinelles Lernen befasst, und ist erforderlich, damit das Modell aus beschrifteten Daten lernen kann. Je besser die Daten beschriftet sind, desto besser werden die Algorithmen funktionieren. Menschliche Bewerter oder Annotatoren müssen bei überwachten Lernalgorithmen häufig Ground-Truth-Labels erstellen, was kostspielig und zeitaufwendig sein kann. Das Papier vergleicht GTD auch mit dem Treibstoff für Schiffsmotoren, wobei DL-Modelle als Motor und riesige Datenmengen als Treibstoff dienen. Mit zunehmender Menge an Trainingsdaten werden DL-Modelle tendenziell besser, und das Zeitalter von Big Data bietet große Chancen für zukünftige DL-Verbesserungen.
Kosten- und Verlustfunktion
Der Zweck der Konstruktion eines DL-Modells besteht darin, die Differenz zwischen den vorhergesagten und den tatsächlichen Werten zu verringern. Dies wird durch die Verwendung von Verlustfunktionen erreicht, die mit jedem Trainingsbeispiel verbunden sind. Die Kostenfunktion wird berechnet, indem man den Durchschnitt der Verlustfunktionswerte über alle Datenbeispiele bildet. Um den DL-Fehler zu verringern, wird die Kostenfunktion optimiert. Durch die Verbesserung der Kostenfunktion können wir die besten Ergebnisse bei DL erzielen.
Metriken
Die Matrizen, die für die Bewertung der Leistung von Modellen des maschinellen Lernens nützlich sind. Wenn es zu Klassifizierungsfehlern kommt, werden Konfusionsmatrizen erstellt, die vier mögliche Werte haben: Wahr Positiv, Falsch Negativ, Falsch Positiv und Wahr Negativ. Die Konfusionsmatrix kann zur Bestimmung von Klassifizierungsmetriken wie Sensitivität, Spezifität, Genauigkeit, negativer Vorhersagewert und Präzision verwendet werden.
Mean Average Precision (mAP)
Die Konfusionsmatrix, die Intersection over Union (IoU), der Recall und die Präzision sind alle Teil der Berechnung der Mean Average Precision (mAP). Sie berechnet den gewichteten Mittelwert der Präzisionen bei jedem Schwellenwert, wobei die Erhöhung der Rückrufquote gegenüber dem vorhergehenden Schwellenwert berücksichtigt wird. Die mAP wird berechnet, indem die AP für jede Klasse berechnet und die Ergebnisse dann über viele Klassen gemittelt werden. Sie ist eine hilfreiche Statistik für die meisten Erkennungsanwendungen, da sie den Kompromiss zwischen Genauigkeit und Rückruf misst.
Intersection over Union (IoU)
Der übliche Standard zur Bewertung der Segmentierung ist „Intersection over Union“. Dieser Wert zeigt die Überlappung der vorhergesagten Bounding-Box-Koordinaten mit den Koordinaten der echten Box an. Ein hoher IoU-Wert zeigt an, dass die vorhergesagten Bounding-Box-Koordinaten den wahren Box-Koordinaten sehr ähnlich sind.
Erstellung von GTD
Auswahl des Datensatzes
In dieser Arbeit besteht das Ziel darin, das effektivste Deep Learning-Modell zur Erkennung von kolorektalem Krebs (CRC) zu identifizieren. Es werden zwei verschiedene Datensätze verwendet: einer mit 1,6k Annotationen und ein anderer mit 4,3k Annotationen. Das Hauptziel ist es, zu untersuchen, wie die Menge an Annotationen die Leistung unseres CRC-Erkennungsmodells beeinflusst. Dazu wird mit beiden Datensätzen separat trainiert, um deren jeweilige Leistungen direkt vergleichen zu können. Diese Analyse wird es uns ermöglichen, festzustellen, ob eine größere Anzahl an Annotationen (4,3k) bessere Ergebnisse bei der CRC-Erkennung im Vergleich zu einer kleineren Anzahl an Annotationen (1,6k) liefert.
Deep Learning-Modelle für CRC
Nach der Erstellung der GTD, um die Modelle zu erstellen, die Schritte zum Beginn des Trainings für ein Deep Learning-Modell mit der HSA KIT-Software. Um zu beginnen, muss ein Modelltyp gewählt werden. Dies wird als Instanz-Segmentierung oder Segmentierung bezeichnet. Die Strukturen, auf denen das Modell trainiert werden soll, müssen dann ausgewählt werden. Dann können Sie im Panel „Augmentierungen“ angeben, dass auch alternative Zell
Orientierungen erkannt werden. Das Modell muss dann benannt werden. Danach werden die Modellarchitektur, die Datensatz-Einstellungen und die Hyperparameter für das Modelltraining festgelegt. Schließlich kann das Training beginnen. Die untenstehende Tabelle zeigt die verschiedenen trainierten Modelle.
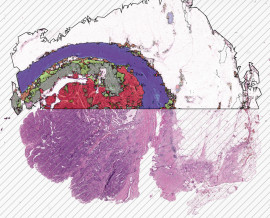
Um Ground-Truth-Daten für das Training eines Deep Learning-Modells zur Erkennung und Klassifizierung von kolorektalem Krebs zu generieren, wird ein mehrstufiger Prozess verfolgt. Zunächst werden Proben von Personen mit kolorektalem Krebs entnommen, typischerweise in Form von Gewebeschnitten. Diese Proben werden dann Färbeverfahren wie Hämatoxylin und Eosin (HE), Ki67 und CRC-Färbungen unterzogen. Der nächste entscheidende Schritt besteht in der Nutzung einer proprietären Software namens HSA KIT. Diese Software unterstützt bei der automatischen oder manuellen Definition der Regionen von Interesse (ROIs) innerhalb der Proben. Innerhalb dieser ROIs werden mithilfe der HSA KIT-Tools sorgfältig Annotationen erstellt, die sich auf die Identifizierung von kolorektalem Krebs und dessen Kategorisierung in drei verschiedene Strukturen konzentrieren: Gesundes Gewebe, Adenom und Karzinom. Darüber hinaus umfasst die abschließende Verfeinerung der Ground-Truth-Daten die manuelle Annotation der Zielbereiche innerhalb der ausgewählten ROIs, indem die Konturen der interessierenden Objekte sorgfältig nachgezeichnet werden. Dieser umfassende Prozess stellt sicher, dass qualitativ hochwertige annotierte Daten zur Verfügung stehen, die für das Training eines genauen Deep Learning-Modells zur Analyse von kolorektalem Krebs unerlässlich sind.
Nach der Erstellung der GTD wurden weitere GTDs erstellt, um das Modell zu verbessern. Beim ersten Mal wurde das Modell mit 1647 GTD (1.6K) trainiert. Beim zweiten Mal wurde das Modell mit 4631 GTD (4.6K) trainiert. Die Klassenverteilung und deren Prozentsätze in den erstellten Daten sind in der untenstehenden Tabelle angegeben.



Auswahl des Datensatzes
Ziel dieser Arbeit ist es, das effektivste Deep-Learning-Modell für die Erkennung von Darmkrebs (CRC) zu identifizieren. Es werden zwei verschiedene Datensätze verwendet: einer mit 1,6k Annotationen und ein anderer mit 4,3k Annotationen.
Das primäre Ziel ist es, zu untersuchen, wie die Menge der Annotationen die Leistung unseres CRC-Erkennungsmodells beeinflusst. Zu diesem Zweck werden beide Datensätze getrennt trainiert, um einen direkten Vergleich der jeweiligen Leistungen zu ermöglichen.
Diese Analyse wird es uns ermöglichen festzustellen, ob eine größere Anzahl von Anmerkungen (4,3k) bessere Ergebnisse bei der Erkennung von CRCs liefert als ein kleinerer Satz von Anmerkungen (1,6k).
Deep Learning-Modelle für CRC
Nach der Erstellung der GTD, um die Modelle zu erstellen, die Schritte, um das Training für ein Deep-Learning-Modell mit der HSA KIT-Software zu beginnen. Zu Beginn muss ein Modelltyp ausgewählt werden. Dies wird als Instanzsegmentierung oder Segmentierung bezeichnet. Anschließend müssen die Strukturen ausgewählt werden, auf denen das Modell trainiert werden soll.
Anschließend können Sie im Feld „Erweiterungen“ angeben, dass auch alternative Zellorientierungen
Orientierungen ebenfalls erkannt werden. Dem Modell muss dann ein Name gegeben werden. Danach werden die Modellarchitektur, die Datensatzeinstellungen und die Hyperparameter für das Training des Modells festgelegt.
Finally, the training can begin. Table below shows the different models that were trained.


Ergebnisse


HyperCrcNet
Das HSA KIT integriert HyperCrcNet, ein Deep Learning-Modell, das speziell für die Bildgebung von kolorektalem Krebs (CRC) entwickelt wurde. HyperCrcNet hat zwei Versionen:
- Typ 1, basierend auf der Vision Transformer (ViT)-Architektur, konzentriert sich auf Instanz-Segmentierung.
- Typ 2, unter Verwendung der U-Net-Architektur, für Segmentierung.
Interpretation der trainierten Modell-Ergebnisse
Die in der untenstehenden Tabelle dargestellten Einstellungen wurden ausgewählt, um die Modelle zu trainieren. Verlust und mAP wurden verwendet, um die Modelle zu vergleichen, wobei ein niedrigerer Verlust und ein höherer mAP wünschenswerte Eigenschaften für ein besseres Modell sind. Der Verlust und die mAP von HyperCrcNet (Typ 1) und HyperCrcNet (Typ 2) Modellen wurden mit gemessenem Verlust und IoU für die 1,6K- und 4,6K-GTD-Modelle verglichen.
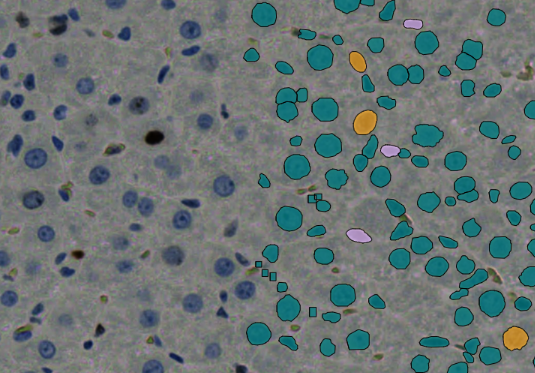
Visuelle Interpretation der Ergebnisse
Nach Abschluss des KI-Trainings für jedes Modell ist die Bewertung der trainierten Modelle wichtig für den Benutzer, wir haben immer eine numerische Bewertung. Das trainierte Modell wurde möglicherweise numerisch getestet und es liefert ein vernünftiges Ergebnis. Es wird immer Zahlen als Ergebnis geben und es ist möglich, durch Zufall ein vernünftiges Ergebnis zu erzielen, das aber tatsächlich falsch sein könnte. Aus diesem Grund muss das Ergebnis immer visuell überprüft werden, bevor man dem KI-Modell vertraut, und man sollte sich nicht nur auf Zahlen verlassen. Nach der Erstellung eines vertrauenswürdigen KI-Modells kann es sicher verwendet werden, vollständig automatisiert und unter der Kontrolle der KI. In diesem Abschnitt werden die Ergebnisse visuell interpretiert. Und dieser Abschnitt illustriert die Visualisierung der Instanz-Segmentierung und Segmentierung beider (Typ 1 & 2) KI-Modelle der CRC-Bilder.
Die folgende Abbildung zeigt einen bestimmten Bereich, ohne dass ein Modell darauf angewendet wurde, einschließlich der „Gesund“-Struktur.
ist der gleiche Bereich mit von mir spezifizierten manuellen Annotationen. Das Ergebnis von HyperCrcNet (Typ 1) bezieht sich auf das Modell, das sowohl mit 1.6K als auch 4.6k GTD trainiert wurde.