“Explainable Deep Learning” (xDL) refers to the use of learning techniques in a manner that allows for transparency and interpretability, in the decision making process of the model. Essentially xDL aims to enhance the comprehensibility of learning models for humans particularly experts in specific domains. It does so by offering insights into how the model reaches its predictions or classifications. This becomes particularly significant in fields such as toxicology, where comprehending the rationale behind a models predictions can assist researchers in making informed decisions especially when it comes to early stage drug development, for heart disease.
Heart
Heart is the main organ of the cardiovascular system, a network of blood vessels that pumps blood throughout the body, with characteristics encompassing both mechanical and electrical aspects. Its mechanical abilities enable it to effectively circulate blood throughout the body while its electrical properties govern the timing and synchronization of its contractions. The hearts electrical system comprises cells for generating and transmitting electrical signals. These signals orchestrate the coordinated contraction and relaxation of the heart muscle thereby facilitating blood pumping. By employing models we can gain an understanding of the hearts functionality and its responses, under various circumstances. One example of a heart muscle model is the cardiomyocyte model. This particular model imitates the mechanical behavior of heart muscle cells, by utilizing the cardiomyocyte model researchers can explore how various medications or treatments impact both the mechanical properties of these heart muscle cells. This helps enhance our understanding of how such interventions influence function. Additionally this model offers an avenue to examine how genetic mutations affect heart muscle cells shedding light on the causes behind inherited conditions.

Cardiomyocytes
Cardiomyocytes also referred to as myocardiocytes or cardiac muscle cells are cells that form the majority of the myocardium, which the heart’s muscular tissue. These cells have similarities to muscle cells. Possess distinct characteristics. Myocardocytes have a branching structure with interconnected projections known as discs. Additionally, they contain mitochondria for generating the energy needed for the heart continuous pumping action. The autonomic nervous system plays a role in regulating the activity of myocardocytes through its sympathetic and parasympathetic branches. Sympathetic stimulation increases both heart rate and contraction force while parasympathetic stimulation has an effect, by slowing down heart rate.

The heart consists of three layers; the endocardium, myocardium and epicardium. The middle layer of the heart is called the myocardium. It is responsible for contracting and relaxing the heart walls to pump blood throughout the body. It acts as a layer, between the endocardium and the outer epicardium, which surrounds and safeguards the heart. Additionally the myocardial cells serve as both components of the heart chambers and conductors of signals.

Whole slide images (WSI)
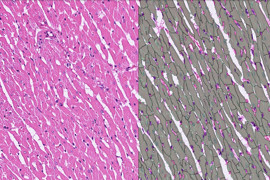
A whole slide image (WSI) is a digital pathology often relies on the use of slide images, which involves analyzing tissue samples using technology. These images have a range of applications, including diagnosis, research and education. Pathologists and researchers can remotely view these images collaborate with colleagues and efficiently analyze amounts of data, with accuracy and speed. Scanning generates an enormous amount of square picture frames, known as tiles (refer Figure 2), which are subsequently arranged in a mosaic pattern. The tiles provide a high-resolution image. To display the individual tiles as a whole, software is required, which then integrates the tiles into an image

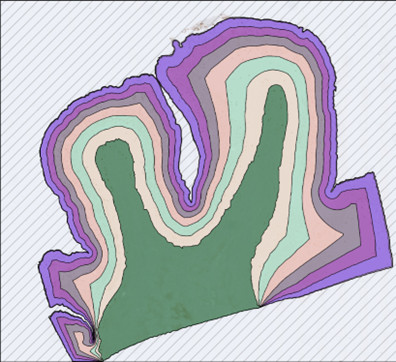
Image Pyramids are a series of image resolutions that range from detailed to general. They play a role in analyzing images at scales. An Image Pyramid is constructed by applying a compression algorithm to the image and arranging it in layers (refer to Figure 3). The original images form the level of the Image Pyramid while the resolution decreases as you move up from the base.

The digital file, for the slide, does not contain a high resolution image. Also includes multiple zoom levels to accommodate the need for both detailed resolution and in depth exploration. This enables the system to adjust the magnification on the screen and retrieve data from the zoom level, for reading purposes.
Difference between the toxicological lab in research of heart diseases for early stage drug development
In the stages of developing drugs for heart diseases, both toxicological and pathological laboratories play roles although their focuses and methodologies differ based on their areas of expertise.
Role of Toxicological Lab, in Early Stage Drug Development for Heart Diseases
During stage early drug development a toxicological lab concentrates on examining the safety and potential toxicity of drug candidates intended for treating heart diseases. Researchers in this lab assess whether these proposed drugs have any effects on the system or other organs. The ultimate goal is to identify any risks associated with using the drug and establish dosage ranges.
Role of Pathological Lab in Early Stage Drug Development for Heart Diseases
In early stage drug development a pathological lab provides insights into how drug candidates may affect the structure and function of the heart. Pathologists and researchers in this lab evaluate how the drug interacts with heart tissues and whether any changes occur that could impact heart health.

Digitization of Slides

The slides are digitalized using the software HSA SCAN, which was created by the company HS Analysis GmbH. HSA SCAN converts physical slides into digital files. Additionally, the HSA SCANNER is applied, which is a hardware product that converts an analog microscope to a digital microscope at a cheap price.

The software’s user-friendly interface allows for easy navigation and customization of scanning settings to meet specific needs. Additionally, the integration with HSA KIT software allows for advanced image analysis and interpretation, providing valuable insights for research and diagnosis. Overall, HSA SCAN software offers a comprehensive solution for labs seeking to streamline their slide digitization process while maintaining quality control.

HSA just needs the microscope’s dimensions and any specifications, and a customised stand and motor for the microscope will be produced. This technology removes the need for human modifications while providing consistent results.
This will aid in:
- Scanning accurately and quickly
- Keeping budget in check: Less expensive than automatic scanners
- Saving time: Automates tasks that require manual intervention
- Better workflow and quality results: reduced risk of errors or inconsistencies
- Intuitive, user friendly controls: Anyone with limited experience with microscopes can operate
Morphological Assessment of the Rodent Cardiomyocyte
Morphological assessment of the rodent cardiomyocyte was performed in order to evaluate the structure and function of these cells. The study was conducted using microscopy, electron microscopy, fluorescent probes, and biochemical assays.
The results of the study showed that rodent cardiomyocytes are elongated cells with a central nucleus. Sarcomere structure was found to be intact, indicating normal contractile function. Mitochondria were abundant and well-structured, indicating high energy demands of these cells. Calcium handling within the cells was normal, suggesting that the cells were capable of proper contraction. Intercalated discs were well-defined, which is important for electrical and mechanical coupling between cells.
Overall, the results of the morphological assessment of rodent cardiomyocytes suggest that these cells have normal structure and function. These findings are important for understanding the normal physiology of the heart and may help identify potential mechanisms of disease. Further studies are needed to assess the functional significance of these findings and their relevance to cardiac disease.
Cardiomyocyte maturation gained increased attention recently due to the maturation defects in pluripotent stem cell-derived cardiomyocyte, its antagonistic effect on myocardial regeneration, and its potential contribution to cardiac disease. Here, we review the major hallmarks of ventricular cardiomyocyte maturation and summarize key regulatory mechanisms that promote and coordinate these cellular events. With advances in the technical platforms used for cardiomyocyte maturation research, we expect significant progress in the future that will deepen our understanding of this process and lead to better maturation of pluripotent stem cell-derived cardiomyocyte and novel therapeutic strategies for heart disease.
Morphological Assessment of the Rodent Myocardium
Morphological assessment of the rodent myocardium involves the examination of the structure, organization, and composition of the heart muscle tissue in rodents. This type of assessment is crucial for understanding cardiac development, function, and potential pathological changes. Here’s a general guide on how to perform a morphological assessment of the rodent myocardium:
Sample Preparation:
- Obtain rodent hearts (usually mice or rats) for analysis. These can be from normal or disease models.
Histological Processing:
- After fixation, the hearts need to be processed for histology.
Staining:
- Hematoxylin and eosin (H&E) staining is commonly used to visualize cellular details and overall tissue architecture.
Microscopic Examination:
- Examine the stained tissue sections under a light microscope, look for changes in cellular morphology, tissue organization, and any signs of disease, such as hypertrophy, fibrosis, or inflammation.
Quantitative Analysis:
- HSA KIT Software can aid in quantifying parameters like cardiomyocyte size, fibrosis area, and capillary density.
Data Interpretation:
- Correlate morphological changes with physiological or pathological conditions and about the effects of treatments, diseases, drug development or experimental manipulations on the myocardium.
HSA KIT Software
HS analysis that provides services related to quality control and analysis of raw materials and finished products in various industries, including pharmaceuticals, cosmetics, food, and agriculture. The company offers a range of analytical services, including chemical and physical testing, microbiological analysis, and stability testing.
The HS Analysis software can help medical professionals develop disorders by examining high-resolution images of tissues and organs. And as the program generates data describing the patient’s current condition, it will assist doctors in selecting appropriate developing.

- As a digital assistant for evidence-based healthcare, software designed particularly for AI.
- To utilise and train the AI, no programming skills are necessary.
- Deep Learning training may be done offline.
- Application interface that is simple to use.
- As a digital assistant for evidence-based healthcare, software designed particularly for AI
- The outcomes are objective, traceable, and reproducible.
HSA KIT Software of Cardiomyocyte
The HS Analysis Deep learning software is able to detect a the Cardiomyocyte by two different cells:
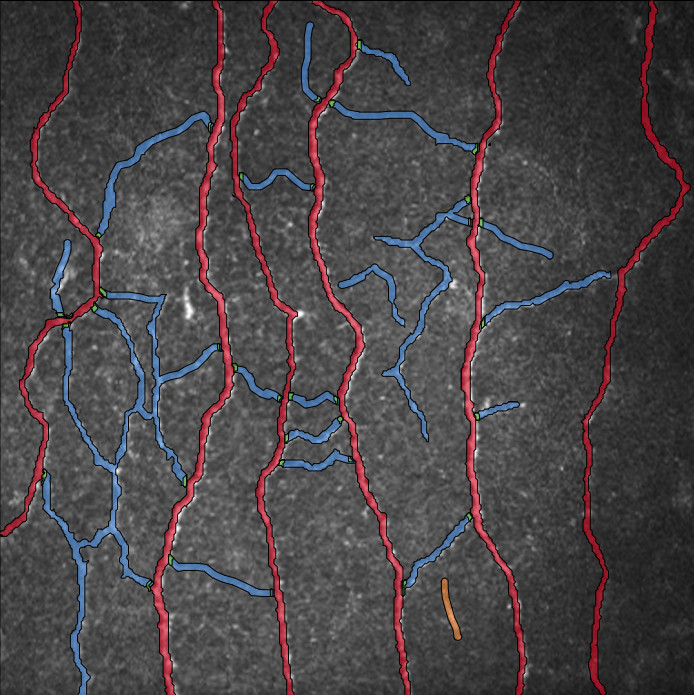
A transverse section of cardiac muscle refers to a cross-sectional view of the myocardium, which is the muscular tissue of the heart. This section is obtained by cutting the heart perpendicular to its longitudinal axis. Here are some key features you would typically observe in a transverse section of cardiac muscle:
- Cardiomyocytes: The primary component of cardiac muscle tissue, cardiomyocytes are elongated cells arranged in a branching network. In a transverse section, you would see multiple cardiomyocytes cut across their width.
- Nuclei: Cardiomyocyte nuclei are typically centrally located within the cells. In a transverse section, you would observe the round or oval nuclei within each cardiomyocyte.
- Blood Vessels: Transverse sections of cardiac muscle also reveal the presence of blood vessels. Coronary arteries and veins supply oxygenated blood to the heart muscle and drain deoxygenated blood from it.




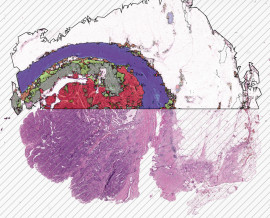
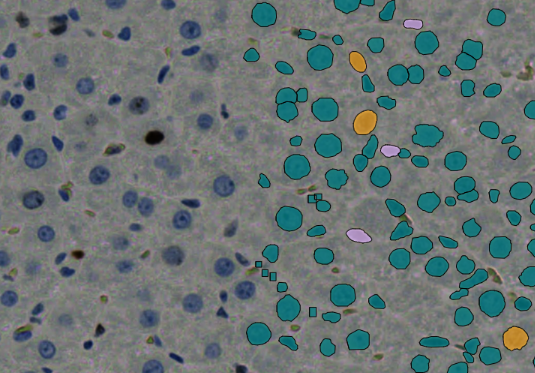
In HSA KIT, pixel-based segmentation and classification of annotated Cardiomyocyte cells was performed using Deep Learning Also, differentiate:
1-Transverse section of cardiac muscle

In transverse section, cardiac muscle is identified by central nuclei and a large ring of surrounding cytoplasm. You may notice a high density of blood vessels and a relatively high proportion of cells that have been sectioned through the nucleus. These features would enable you to distinguish between cardiac and smooth muscle.
- Central Nuclei
- Cytoplasm to Nucleus area ratio is high
- Nuclei are visible in many ventricular cells in transverse section (compared to very few nuclei in TS of smooth muscle)
2. Longitudinal section of cardiac muscle

Normal cardiac muscle in longitudinal section shows a syncytium of myocardial fibers with central nuclei. Faint pink intercalated discs cross some of the fibers. Red blood cells are seen in single files in capillaries between the fibers.
- Central nuclei (often football-shaped with relatively large ring of cytoplasm surrounding it)
- Striations
- branching
HSA KIT Software of Myocardium
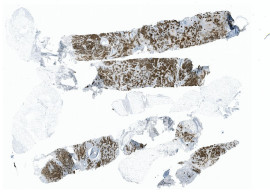
In HS Analysis annotate the myocardium by first to select the region of interested and remove huge white gab and then to annotate the big area of myocardium.
To detect and analyze the myocardium, especially in medical contexts, several imaging and techniques are commonly used, the HS Analysis Deep learning software is able to detect a the Myocardium:

The myocardium is primarily composed of specialized muscle tissue known as cardiac muscle cells or cardiomyocytes. These cells are responsible for the contractile function of the heart, allowing it to pump blood throughout the circulatory system. The myocardium also contains various components that contribute to its overall structure and function. Here are some key components found in the myocardium:
- Cardiomyocytes
- Interstitium
- Blood Vessels
- Extracellular Matrix (ECM)
- Mitochondria
- Sarcoplasmic reticulum
Deep learning (DL)
Deep learning, a branch of AI and machine learning is dedicated to training neural networks to learn from extensive data sets and make predictions or decisions. This advanced approach enables the recognition of patterns and accurate predictions, in domains such as image and speech recognition well, and natural language processing.
Machine learning (ML) is a subfield of artificial intelligence (AI) that focuses on developing algorithms and models that allow computers to learn and improve their performance on projects without the need for explicit programming. Machine learning systems gather information from data and gradually enhance their performance via experience Neural networks are a type of machine learning technology that replicates the structure and operation of the networks in biological neural networks of the human brain. They are made up of linked nodes that analyses and send information, allowing them to learn from data sets.

Ground Truth Data of myocardium and cardiomyocyte
Within the field of machine learning, ground truth data (GTD) refers to the comprehensive information used for training models. When it comes to heart muscle models (GTD) plays a role, in training machine learning algorithms to identify and categorize types of cells and tissues present, in image data. This involves labelling the image data with indications of cell or tissue location and type. By using these annotated datasets we can teach machine learning models to recognize and classify cells and tissues within images.
The following is a general procedure for creating a large-scale dataset with ground truth labels:
- Planning: When starting a project the initial phase involves identifying the specifications needed for the algorithms that will be utilized in training, with the data.
- Data privacy and compliance: Before commencing the project, it is necessary to check with the organization’s legal or compliance operations to evaluate the compliance implications of collecting the data.
- Project design: Researchers plan the project, including determining the data sources estimating the number of participants, for data collection and establishing methods to validate the data and maintain its quality.
- Annotation: The team of a group of annotators who examine data samples and provide annotations based on the project requirements.
- Reviewing data quality: Once the datasets have been prepared, the team examines the quality of the annotations as well as any assumptions that the datasets may have. Because the trained model is only as good as its training data, this phase is crucial to ensuring satisfactory model performance.
It is necessary to ensure the reliability and authenticity of ground truth data. Any defects or biases in the classification process can have an influence on the trained machine learning model’s performance and ability to generalize. Obtaining high-quality ground truth data may sometimes be a time-consuming and costly efforts, especially for positions that need professional expertise or extensive annotations.
Here we have heart project and we will annotate 2 important things of the world wide cardiomyocyte and myocardium here this table show us (name of files, name of projects, number of annotations cardiomyocyte, number of annotations myocardium, number of base ROI , and total number of annotations) first we begin with annotation cardiomyocyte in 3 files and we did a lot of correction to show us correct of annotation and in the end number of annotation of cardiomyocyte was too much and myocardium also we put in 8 files to annotation because annotation of myocardium is to annotate the whole heart expect the white gap.

DL models seem to improve with increasing quantities of training data, however standard machine learning models pause at a certain point. In many circumstances, human assessors or annotators must construct ground truth labels. This is both costly and time demanding, especially if the dataset contains a large number of records. To allow DL, massive volumes of data are collected. The modern age of big data will bring great opportunities for future DL improvements.
Regularization
Regularization is a technique in machine learning that serves the purpose of preventing overfitting. Overfitting occurs when a model becomes overly complex and starts memorizing the training data of learning patterns that can be applied to new and unseen data. The main goal of regularization is to strike a balance between fitting the training data while maintaining generalization abilities for new data.
On the hand underfitting happens when a model is too simplistic and fails to capture the core patterns within the data. It struggles to learn from the training data and as a result also performs poorly on data. Underfitting is typically observed when the model lacks complexity in representing the underlying relationships in the data.
Overfitting takes place when a model becomes overly intricate and captures information or random fluctuations from the training data of capturing the actual patterns. This leads to accuracy, on the training set but poor performance when faced with unseen data. Overfitting often occurs when a model has a number of parameters compared to the training data allowing it to fit the noise rather than the true underlying relationship.

Model Training
The HS Analysis GmbH company’s customer provided the samples used in this study, which were sourced from individuals with heart-related conditions. The preparation process involved slicing the tissue, mounting it on slides, and applying various staining techniques, including Hematoxylin and Eosin (H&E staining), Immunohistochemistry (IHC), and hemalum staining. These stained slides were then transformed into digital NDPI files through scanning. Subsequently, these NDPI files were submitted to the company to develop a Deep Learning (DL) model. The NDPI files were loaded in HSA KIT software.
- Begin by clicking the plus icon labeled “Add new project.”
- Then, select the “Annotator” option.
- Afterward, choose the specific NDPI file that intend to annotate.
- The next step involves selecting the base or Region of Interest (ROI) for creating GTD for the project that to be annotating.
- Following that, proceed to annotate two distinct projects: “Myocardium” and “Cardiomyocyte.” Annotating “Myocardium” entails marking a larger area for annotation, while “Cardiomyocyte” involves identifying and analyzing specific cell types, namely “Transverse” and “Longitudinal” cells.
This comprehensive process enabled the development of a DL model capable of analyzing of heart tissue, contributing to the understanding and development of heart-related conditions. The creation of high-quality Ground Truth Data played a critical role in training and validating the model for accurate and reliable results.
For the training procedure within HSA KIT, it’s essential to…
4-Select possible transformations (Augmentation): During the training of machine learning models, particularly deep learning models for image classification or object detection, data augmentation is a widely used method to enhance the variety within the training dataset and enhance the model’s ability to generalize.

5-Meta Data: The option to either train a new model or begin training using an existing one: ” Start from scratch by entering the name for new mode”.”Utilize an existing model by choosing the desired model name and version”.

6-Advanced settings: Choosing from advanced settings commonly pertain to configuration choices and parameters that are tunable during the training of machine learning or deep learning models. These options provide a higher level of precision in managing the training process and can have an influence on the model’s performance.

1-To initiate the training process, select “Train Model,” and then proceed to create a new model by clicking on “Train Custom AI Model.”

2-Select model type: The development of AI systems in a variety of applications and domains is based on these model training types, which allow machines to learn from data and make valid results. The challenge at hand and the availability of labelled data determine the training technique to be used.

3-Select the structure: Choosing the structure for the training process entails deciding on the architectural framework that will be employed to build and train AI model.

Workflow with HSA KIT
Analyzing samples and digitizing slides has never been more effortless. HSA KIT offers an unparalleled experience to its customers who seek to embrace more advanced alternatives and enhance their workflow efficiency. The HSA team goes to great lengths to satisfy its clients, assisting with software installation, integration, and providing continuous support and updates.
Using AI-based analysis with HSA KIT, you can expect:
- Standardized processes encompassing both subjective and objective analysis.
- Extraction of pertinent features from raw data, generating meaningful representations for training AI models.
- Module selection and configuration without the need for extensive coding.
- User-friendly software that is easy to learn, enabling annotation, training, and automation.
- Swift and effective analysis of numerous medical images, reducing diagnosis or treatment time.
- Automated report generation to enhance productivity and aid physicians or radiologists in the evaluation process.

Metrics
A number of metrics are used to assess the performance of algorithms for interpreting medical images. The confusion matrix is a table that is used to visualize algorithm performance and calculate several assessment measures. Confusion matrices are used to assess deep learning models and provide a more precise representation of their performance. In deep learning, metrics refer to quantitative measures used to evaluate the performance of a machine learning model.
These metrics provide insights into how well a model is performing on a given task and can help developers and practitioners make informed decisions about model selection, optimization, and fine-tuning. This article aims to briefly explain the definition of commonly used metrics in machine learning, including Accuracy, Precision, Recall, and F1.
Accuracy measures the overall accuracy of the model performance.

Precision indicates how many predicted Positives are True Positives, out of all Predicted Positive.

Recall measures how many Positives the model predicted correctly, out of all Actual Positive.

F1 is the harmonic mean of precision and recall.