„Erklärbares Deep Learning“ (xDL) bezieht sich auf den Einsatz von Lerntechniken in einer Weise, die Transparenz und Interpretierbarkeit im Entscheidungsprozess des Modells ermöglicht. Im Wesentlichen zielt xDL darauf ab, die Verständlichkeit von Lernmodellen für Menschen, insbesondere für Experten in spezifischen Fachgebieten, zu erhöhen. Dies geschieht durch das Bereitstellen von Einblicken in die Art und Weise, wie das Modell seine Vorhersagen oder Klassifikationen erreicht. Dies wird insbesondere in Bereichen wie der Toxikologie bedeutend, wo das Verständnis der Gründe hinter den Vorhersagen eines Modells den Forschern helfen kann, fundierte Entscheidungen zu treffen, insbesondere bei der frühen Arzneimittelentwicklung für Herzkrankheiten.
Herz
Das Herz ist das Hauptorgan des Herz-Kreislauf-Systems, einem Netzwerk von Blutgefäßen, das Blut durch den Körper pumpt, mit Eigenschaften, die sowohl mechanische als auch elektrische Aspekte umfassen. Seine mechanischen Fähigkeiten ermöglichen es ihm, das Blut effektiv durch den Körper zu zirkulieren, während seine elektrischen Eigenschaften die Timing und Synchronisation seiner Kontraktionen steuern. Das elektrische System des Herzens besteht aus Zellen, die elektrische Signale erzeugen und übertragen. Diese Signale orchestrieren die koordinierte Kontraktion und Entspannung des Herzmuskels und ermöglichen so das Pumpen des Blutes. Durch den Einsatz von Modellen können wir ein Verständnis der Funktionalität des Herzens und seiner Reaktionen unter verschiedenen Umständen gewinnen. Ein Beispiel für ein Herzmuskelmodell ist das Kardiomyozytenmodell. Dieses spezielle Modell imitiert das mechanische Verhalten von Herzmuskelzellen, und durch die Nutzung dieses Modells können Forscher untersuchen, wie verschiedene Medikamente oder Behandlungen die mechanischen Eigenschaften dieser Herzmuskelzellen beeinflussen. Dies hilft, unser Verständnis darüber zu verbessern, wie solche Eingriffe die Herzfunktion beeinflussen. Zusätzlich bietet dieses Modell eine Möglichkeit zu untersuchen, wie genetische Mutationen die Herzmuskelzellen beeinflussen, und gibt Aufschluss über die Ursachen vererbter Erkrankungen.

Kardiomyozyten
Kardiomyozyten, auch als Myokardiozyten oder Herzmuskelzellen bezeichnet, sind Zellen, die den Großteil des Myokards bilden, das das muskuläre Gewebe des Herzens ist. Diese Zellen ähneln Muskelzellen. Sie besitzen jedoch auch einzigartige Eigenschaften. Myokardiozyten haben eine verzweigte Struktur mit verbundenen Projektionen, die als Discs bekannt sind. Zusätzlich enthalten sie Mitochondrien zur Erzeugung der Energie, die für die kontinuierliche Pumpaktion des Herzens benötigt wird. Das autonome Nervensystem spielt eine Rolle bei der Regulierung der Aktivität der Myokardiozyten durch seine sympathischen und parasympathischen Zweige. Sympathische Stimulation erhöht sowohl die Herzfrequenz als auch die Kontraktionskraft, während die parasympathische Stimulation eine Wirkung hat, indem sie die Herzfrequenz verlangsamt.

Das Herz besteht aus drei Schichten: dem Endokardium, Myokardium und Epikardium. Die mittlere Schicht des Herzens wird Myokardium genannt. Es ist verantwortlich für das Kontrahieren und Entspannen der Herzmuskelwände, um Blut durch den Körper zu pumpen. Es fungiert als Zwischenschicht zwischen dem Endokardium und dem äußeren Epikardium, das das Herz umgibt und schützt. Zudem dienen die Myokardzellen sowohl als Bestandteile der Herzkammern als auch als Signalüberträger.

Ganzschichtbilder (WSI)
Ein Ganzschichtbild (WSI) ist eine digitale Pathologie, die häufig auf der Verwendung von Objektträgerbildern basiert, was die Analyse von Gewebeproben mit Technologie umfasst. Diese Bilder haben eine Vielzahl von Anwendungen, darunter Diagnose, Forschung und Bildung. Pathologen und Forscher können diese Bilder aus der Ferne betrachten, mit Kollegen zusammenarbeiten und große Datenmengen effizient analysieren, mit Genauigkeit und Geschwindigkeit. Das Scannen erzeugt eine enorme Menge an quadratischen Bildrahmen, die als Kacheln bekannt sind (siehe Abbildung 2), die anschließend in einem Mosaikmuster angeordnet werden. Die Kacheln liefern ein hochauflösendes Bild. Um die einzelnen Kacheln als Ganzes darzustellen, wird Software benötigt, die die Kacheln zu einem Bild integriert.

Bildpyramiden sind eine Reihe von Bildauflösungen, die von detailliert bis allgemein reichen. Sie spielen eine Rolle bei der Analyse von Bildern in verschiedenen Maßstäben. Eine Bildpyramide wird erstellt, indem ein Komprimierungsalgorithmus auf das Bild angewendet und es in Schichten angeordnet wird (siehe Abbildung 3). Die Originalbilder bilden die unterste Ebene der Bildpyramide, während die Auflösung abnimmt, je weiter man sich vom Sockel entfernt.

Die digitale Datei für den Objektträger enthält kein hochauflösendes Bild. Sie enthält auch mehrere Zoomstufen, um den Bedarf an detaillierter Auflösung und eingehender Erkundung zu decken. Dies ermöglicht es dem System, die Vergrößerung auf dem Bildschirm anzupassen und Daten aus der Zoomstufe für Lesebedürfnisse abzurufen.
Unterschied zwischen dem toxikologischen Labor bei der Erforschung von Herzkrankheiten zur Arzneimittelentwicklung in frühen Phasen
In den Phasen der Entwicklung von Medikamenten für Herzkrankheiten spielen sowohl toxikologische als auch pathologische Labore eine Rolle, obwohl sich ihre Schwerpunkte und Methoden je nach ihrem Fachgebiet unterscheiden.
Rolle des toxikologischen Labors in der Arzneimittelentwicklung in frühen Phasen bei Herzkrankheiten
In der frühen Phase der Arzneimittelentwicklung konzentriert sich ein toxikologisches Labor darauf, die Sicherheit und potenzielle Toxizität von Arzneimittelkandidaten zu untersuchen, die zur Behandlung von Herzkrankheiten bestimmt sind. Forscher in diesem Labor bewerten, ob diese vorgeschlagenen Medikamente irgendwelche Auswirkungen auf das System oder andere Organe haben. Das ultimative Ziel ist es, alle mit der Anwendung des Medikaments verbundenen Risiken zu identifizieren und Dosierungsbereiche festzulegen.
Rolle des pathologischen Labors in der Arzneimittelentwicklung in frühen Phasen bei Herzkrankheiten
In der frühen Phase der Arzneimittelentwicklung liefert ein pathologisches Labor Einblicke, wie sich Arzneimittelkandidaten auf die Struktur und Funktion des Herzens auswirken können. Pathologen und Forscher in diesem Labor bewerten, wie das Medikament mit Herzgeweben interagiert und ob Veränderungen auftreten, die die Herzgesundheit beeinträchtigen könnten.

Digitalisierung von Objektträgern

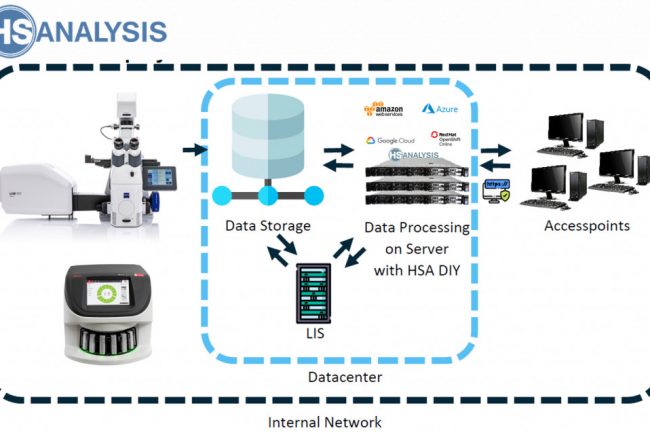
Die Objektträger werden mit der Software HSA SCAN digitalisiert, die von der Firma HS Analysis GmbH entwickelt wurde. HSA SCAN wandelt physische Objektträger in digitale Dateien um. Zusätzlich wird der HSA SCANNER angewendet, ein Hardwareprodukt, das ein analoges Mikroskop zu einem digitalen Mikroskop zu einem günstigen Preis umwandelt.

Die benutzerfreundliche Oberfläche der Software ermöglicht eine einfache Navigation und Anpassung der Scan-Einstellungen an spezifische Bedürfnisse. Zusätzlich ermöglicht die Integration mit der HSA KIT Software eine fortschrittliche Bildanalyse und -interpretation, die wertvolle Einblicke für Forschung und Diagnose bietet. Insgesamt bietet die HSA SCAN Software eine umfassende Lösung für Labore, die ihren Prozess der Objektträger-Digitalisierung optimieren möchten und gleichzeitig die Qualitätskontrolle beibehalten.

HSA benötigt lediglich die Abmessungen und Spezifikationen des Mikroskops, und ein maßgeschneiderter Ständer und Motor für das Mikroskop werden produziert. Diese Technologie beseitigt die Notwendigkeit menschlicher Anpassungen und liefert dennoch konsistente Ergebnisse.
Dies hilft bei:
- Genauem und schnellem Scannen
- Budgeteinhaltung: Kostengünstiger als automatische Scanner
- Zeitersparnis: Automatisiert Aufgaben, die manuelle Eingriffe erfordern
- Besserem Arbeitsablauf und hochwertigen Ergebnissen: Reduziertes Risiko von Fehlern oder Inkonsistenzen
- Intuitive, benutzerfreundliche Steuerung: Auch Personen mit begrenzter Mikroskoperfahrung können es bedienen
Morphologische Bewertung des Kardiomyozyten bei Nagetieren
Die morphologische Bewertung des Kardiomyozyten bei Nagetieren wurde durchgeführt, um die Struktur und Funktion dieser Zellen zu bewerten. Die Studie wurde unter Verwendung von Mikroskopie, Elektronenmikroskopie, fluoreszierenden Sonden und biochemischen Tests durchgeführt.
Die Ergebnisse der Studie zeigten, dass Kardiomyozyten bei Nagetieren längliche Zellen mit einem zentralen Zellkern sind. Die Struktur der Sarkomere war intakt, was auf eine normale kontraktile Funktion hindeutet. Mitochondrien waren zahlreich und gut strukturiert, was auf den hohen Energiebedarf dieser Zellen hinweist. Der Kalziumhaushalt in den Zellen war normal, was darauf hindeutet, dass die Zellen ordnungsgemäß kontrahieren können. Die Glanzstreifen waren gut definiert, was für die elektrische und mechanische Kopplung zwischen den Zellen wichtig ist.
Insgesamt deuten die Ergebnisse der morphologischen Bewertung der Kardiomyozyten bei Nagetieren darauf hin, dass diese Zellen eine normale Struktur und Funktion aufweisen. Diese Erkenntnisse sind wichtig für das Verständnis der normalen Herzphysiologie und können dazu beitragen, potenzielle Mechanismen von Erkrankungen zu identifizieren. Weitere Studien sind erforderlich, um die funktionelle Bedeutung dieser Ergebnisse und ihre Relevanz für Herzerkrankungen zu bewerten.
Die Reifung von Kardiomyozyten hat in letzter Zeit vermehrt Aufmerksamkeit erlangt, aufgrund von Reifungsdefekten in aus pluripotenten Stammzellen gewonnenen Kardiomyozyten, deren antagonistischen Effekten auf die Myokardregeneration und ihrem potenziellen Beitrag zu Herzerkrankungen. Hier fassen wir die wichtigsten Merkmale der Reifung von ventrikulären Kardiomyozyten zusammen und beleuchten zentrale regulatorische Mechanismen, die diese zellulären Prozesse fördern und koordinieren. Mit Fortschritten in den technischen Plattformen, die für die Forschung zur Kardiomyozytenreifung eingesetzt werden, erwarten wir in Zukunft erhebliche Fortschritte, die unser Verständnis dieses Prozesses vertiefen und zu einer besseren Reifung aus pluripotenten Stammzellen gewonnener Kardiomyozyten sowie zu neuen therapeutischen Strategien für Herzerkrankungen führen werden.
Morphologische Bewertung des Myokards bei Nagetieren
Die morphologische Bewertung des Myokards bei Nagetieren umfasst die Untersuchung der Struktur, Organisation und Zusammensetzung des Herzmuskelgewebes bei Nagetieren. Diese Art der Bewertung ist entscheidend für das Verständnis der Herzentwicklung, Funktion und potenziellen pathologischen Veränderungen. Hier ist eine allgemeine Anleitung, wie man eine morphologische Bewertung des Myokards bei Nagetieren durchführt:
Probenvorbereitung:
- Entnahme von Nagetierherzen (in der Regel von Mäusen oder Ratten) zur Analyse. Diese können aus normalen oder Krankheitsmodellen stammen.
Histologische Verarbeitung:
- Nach der Fixierung müssen die Herzen für die Histologie aufbereitet werden.
Färbung:
- Hämatoxylin- und Eosin (H&E)-Färbung wird häufig verwendet, um zelluläre Details und die allgemeine Gewebearchitektur zu visualisieren.
Mikroskopische Untersuchung:
- Untersuchen Sie die gefärbten Gewebeschnitte unter einem Lichtmikroskop und achten Sie auf Veränderungen in der Zellmorphologie, der Gewebeorganisation und auf Anzeichen von Krankheiten wie Hypertrophie, Fibrose oder Entzündung.
Quantitative Analyse:
- Die HSA KIT Software kann bei der Quantifizierung von Parametern wie Kardiomyozytengröße, Fibrosefläche und Kapillardichte helfen.
Dateninterpretation:
- Korrelieren Sie morphologische Veränderungen mit physiologischen oder pathologischen Zuständen und bewerten Sie die Auswirkungen von Behandlungen, Krankheiten, Arzneimittelentwicklung oder experimentellen Manipulationen auf das Myokard.
HSA KIT Software
HS Analysis bietet Dienstleistungen im Zusammenhang mit Qualitätskontrolle und Analyse von Rohstoffen und Fertigprodukten in verschiedenen Branchen, einschließlich Pharmazeutika, Kosmetik, Lebensmittel und Landwirtschaft. Das Unternehmen bietet eine Reihe von analytischen Dienstleistungen an, darunter chemische und physikalische Tests, mikrobiologische Analysen und Stabilitätstests.
Die HS Analysis Software kann Medizinern helfen, Erkrankungen zu entwickeln, indem sie hochauflösende Bilder von Geweben und Organen untersucht. Und da das Programm Daten generiert, die den aktuellen Zustand des Patienten beschreiben, wird es den Ärzten bei der Auswahl geeigneter Entwicklungsmöglichkeiten helfen.

- Als digitaler Assistent für evidenzbasierte Gesundheitsversorgung, Software, die speziell für KI entwickelt wurde.
- Um die KI zu nutzen und zu trainieren, sind keine Programmierkenntnisse erforderlich.
- Deep-Learning-Training kann offline durchgeführt werden.
- Einfach zu bedienende Anwendungsoberfläche.
- Die Ergebnisse sind objektiv, nachvollziehbar und reproduzierbar.
HSA KIT Software für Kardiomyozyten
Die HS Analysis Deep Learning Software ist in der Lage, Kardiomyozyten anhand zweier unterschiedlicher Zelltypen zu erkennen:
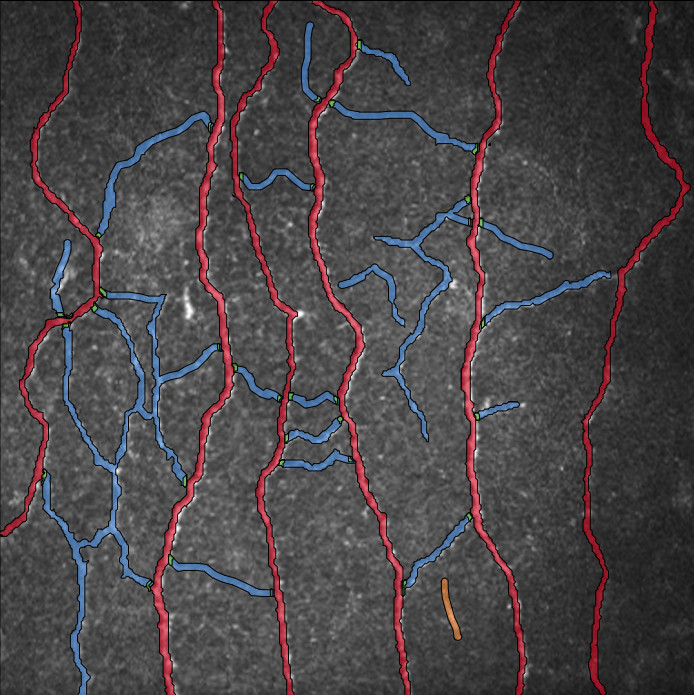
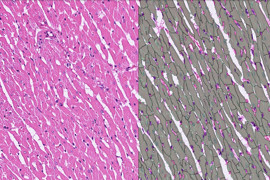
Ein Querschnitt des Herzmuskels bezieht sich auf eine Querschnittsansicht des Myokards, das das muskuläre Gewebe des Herzens ist. Dieser Abschnitt wird durch das Schneiden des Herzens senkrecht zu seiner Längsachse gewonnen. Hier sind einige wichtige Merkmale, die Sie typischerweise in einem Querschnitt des Herzmuskels beobachten würden:
- Kardiomyozyten: Der primäre Bestandteil des Herzmuskelgewebes, Kardiomyozyten, sind längliche Zellen, die in einem verzweigten Netzwerk angeordnet sind. In einem Querschnitt würden Sie mehrere Kardiomyozyten sehen, die quer durch ihre Breite geschnitten wurden.
- Zellkerne: Die Zellkerne der Kardiomyozyten befinden sich typischerweise zentral innerhalb der Zellen. In einem Querschnitt würden Sie die runden oder ovalen Zellkerne innerhalb jedes Kardiomyozyten beobachten.
- Blutgefäße: Querschnitte des Herzmuskels zeigen auch die Anwesenheit von Blutgefäßen. Koronararterien und -venen versorgen den Herzmuskel mit sauerstoffreichem Blut und leiten sauerstoffarmes Blut ab.




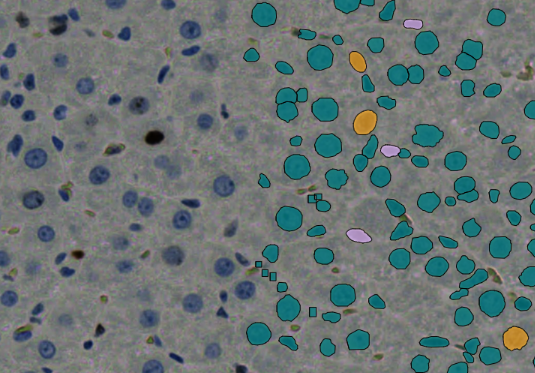
In HSA KIT wurde eine pixelbasierte Segmentierung und Klassifizierung der annotierten Kardiomyozytenzellen mittels Deep Learning durchgeführt. Außerdem wird unterschieden zwischen:
1-Querschnitt des Herzmuskels

2. Längsschnitt des Herzmuskels

HSA KIT Software für das Myokard
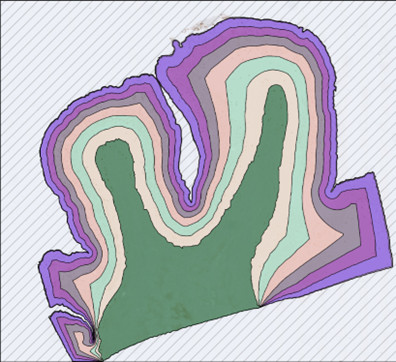
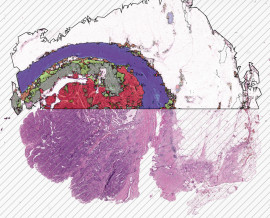
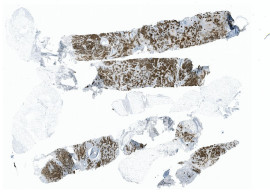
In HS Analysis annotieren Sie das Myokard, indem Sie zuerst den interessierenden Bereich auswählen und große weiße Lücken entfernen, bevor Sie den großen Bereich des Myokards annotieren.
Um das Myokard zu erkennen und zu analysieren, insbesondere in medizinischen Kontexten, werden verschiedene Bildgebungs- und Techniken verwendet, und die HS Analysis Deep Learning Software ist in der Lage, das Myokard zu erkennen:

Das Myokard besteht hauptsächlich aus spezialisiertem Muskelgewebe, das als Herzmuskelzellen oder Kardiomyozyten bekannt ist. Diese Zellen sind für die kontraktile Funktion des Herzens verantwortlich, die es ihm ermöglicht, Blut durch das Kreislaufsystem zu pumpen. Das Myokard enthält auch verschiedene Komponenten, die zu seiner gesamten Struktur und Funktion beitragen. Hier sind einige wichtige Komponenten, die im Myokard zu finden sind:
- Kardiomyozyten
- Interstitium
- Blutgefäße
- Extrazelluläre Matrix (ECM)
- Mitochondrien
- Sarkoplasmatisches Retikulum
Deep Learning (DL)
Deep Learning, ein Zweig von KI und maschinellem Lernen, widmet sich dem Training neuronaler Netzwerke, um aus umfangreichen Datensätzen zu lernen und Vorhersagen oder Entscheidungen zu treffen. Dieser fortschrittliche Ansatz ermöglicht die Erkennung von Mustern und präzise Vorhersagen in Bereichen wie Bild- und Spracherkennung sowie Verarbeitung natürlicher Sprache.
Maschinelles Lernen (ML) ist ein Teilbereich der künstlichen Intelligenz (KI), der sich auf die Entwicklung von Algorithmen und Modellen konzentriert, die es Computern ermöglichen, aus Daten zu lernen und ihre Leistung in Projekten ohne explizite Programmierung zu verbessern. Maschinelle Lernsysteme sammeln Informationen aus Daten und verbessern ihre Leistung allmählich durch Erfahrung. Neuronale Netzwerke sind eine Art maschineller Lerntechnologie, die die Struktur und Funktionsweise biologischer neuronaler Netzwerke im menschlichen Gehirn nachahmen. Sie bestehen aus verbundenen Knoten, die Informationen analysieren und übermitteln, wodurch sie in der Lage sind, aus Datensätzen zu lernen.

Ground Truth Daten des Myokards und Kardiomyozyten
Im Bereich des maschinellen Lernens beziehen sich Ground Truth Daten (GTD) auf die umfassenden Informationen, die zum Trainieren von Modellen verwendet werden. Bei Herzmuskelmodellen spielen GTD eine Rolle beim Trainieren von maschinellen Lernalgorithmen, um Arten von Zellen und Geweben in Bilddaten zu identifizieren und zu kategorisieren. Dies umfasst die Kennzeichnung der Bilddaten mit Hinweisen auf den Ort und Typ der Zelle oder des Gewebes. Durch die Verwendung dieser annotierten Datensätze können wir maschinellen Lernmodellen beibringen, Zellen und Gewebe in Bildern zu erkennen und zu klassifizieren.
Das folgende ist ein allgemeines Verfahren zur Erstellung eines groß angelegten Datensatzes mit Ground Truth Labels:
- Planung: Beim Start eines Projekts besteht die erste Phase darin, die Anforderungen zu identifizieren, die für die Algorithmen erforderlich sind, die mit den Daten trainiert werden sollen.
- Datenschutz und Compliance: Bevor das Projekt beginnt, muss mit den Rechts- oder Compliance-Abteilungen der Organisation abgestimmt werden, um die Compliance-Auswirkungen der Datenerfassung zu bewerten.
- Projektgestaltung: Forscher planen das Projekt, einschließlich der Bestimmung der Datenquellen, der Schätzung der Anzahl der Teilnehmer für die Datenerhebung und der Festlegung von Methoden zur Validierung und Aufrechterhaltung der Datenqualität.
- Annotation: Das Team von Annotatoren, die Datenproben untersuchen und basierend auf den Projektanforderungen Anmerkungen machen.
- Datenqualitätsprüfung: Sobald die Datensätze vorbereitet sind, prüft das Team die Qualität der Anmerkungen und etwaiger Annahmen, die die Datensätze möglicherweise enthalten. Da das trainierte Modell nur so gut ist wie seine Trainingsdaten, ist diese Phase entscheidend, um eine zufriedenstellende Modellleistung sicherzustellen.
Es ist notwendig, die Zuverlässigkeit und Authentizität von Ground Truth Daten sicherzustellen. Mängel oder Verzerrungen im Klassifizierungsprozess können sich auf die Leistung und die Fähigkeit des trainierten maschinellen Lernmodells auswirken. Die Beschaffung hochwertiger Ground Truth Daten kann manchmal eine zeitaufwändige und kostspielige Aufgabe sein, insbesondere für Positionen, die Fachwissen oder umfangreiche Anmerkungen erfordern.
Hier haben wir ein Herzprojekt und wir werden zwei wichtige Dinge der weltweit vorhandenen Kardiomyozyten und Myokardien annotieren. Diese Tabelle zeigt uns (Dateinamen, Projektnamen, Anzahl der Kardiomyozyten-Anmerkungen, Anzahl der Myokard-Anmerkungen, Anzahl der Basis-ROIs und die Gesamtzahl der Anmerkungen). Zuerst beginnen wir mit der Annotation von Kardiomyozyten in drei Dateien und führten viele Korrekturen durch, um uns die korrekte Annotation zu zeigen, und am Ende war die Anzahl der Kardiomyozyten-Anmerkungen sehr hoch. Myokardien haben wir auch in acht Dateien zur Annotation gegeben, da bei der Annotation von Myokard das gesamte Herz annotiert wird, mit Ausnahme der weißen Lücke.

DL-Modelle scheinen sich mit zunehmender Datenmenge beim Training zu verbessern, während Standard-ML-Modelle ab einem bestimmten Punkt pausieren. In vielen Fällen müssen menschliche Gutachter oder Annotatoren Ground Truth Labels erstellen. Dies ist sowohl kostspielig als auch zeitaufwändig, insbesondere wenn der Datensatz eine große Anzahl von Datensätzen enthält. Um DL zu ermöglichen, werden große Datenmengen gesammelt. Das moderne Zeitalter der Big Data wird große Chancen für zukünftige DL-Verbesserungen bringen.
Regularisierung
Regularisierung ist eine Technik im maschinellen Lernen, die den Zweck hat, Overfitting zu verhindern. Overfitting tritt auf, wenn ein Modell zu komplex wird und beginnt, die Trainingsdaten auswendig zu lernen, anstatt Muster zu lernen, die auf neue und ungesehene Daten angewendet werden können. Das Hauptziel der Regularisierung besteht darin, ein Gleichgewicht zwischen der Anpassung an die Trainingsdaten und der Erhaltung der Generalisierungsfähigkeit für neue Daten zu erreichen.
Auf der anderen Seite tritt Underfitting auf, wenn ein Modell zu einfach ist und die wesentlichen Muster in den Daten nicht erfasst. Es hat Schwierigkeiten, aus den Trainingsdaten zu lernen, und zeigt daher auch bei neuen Daten eine schlechte Leistung. Underfitting wird in der Regel beobachtet, wenn dem Modell die Komplexität fehlt, um die zugrunde liegenden Beziehungen in den Daten darzustellen.
Overfitting tritt auf, wenn ein Modell zu kompliziert wird und Informationen oder zufällige Schwankungen in den Trainingsdaten aufnimmt, anstatt die tatsächlichen Muster zu erfassen. Dies führt zu hoher Genauigkeit im Trainingssatz, aber schlechter Leistung bei neuen Daten. Overfitting tritt häufig auf, wenn ein Modell eine große Anzahl von Parametern im Vergleich zu den Trainingsdaten hat, was es ihm ermöglicht, das Rauschen anstelle der tatsächlichen zugrunde liegenden Beziehung anzupassen.

Modelltraining
Die Proben, die in dieser Studie verwendet wurden, stammten vom Kunden der HS Analysis GmbH und wurden von Personen mit Herzerkrankungen bezogen. Der Vorbereitungsprozess umfasste das Schneiden des Gewebes, das Aufbringen auf Objektträger und das Anwenden verschiedener Färbetechniken, einschließlich Hämatoxylin und Eosin (H&E-Färbung), Immunhistochemie (IHC) und Hämalaun-Färbung. Diese gefärbten Objektträger wurden dann durch Scannen in digitale NDPI-Dateien umgewandelt. Anschließend wurden diese NDPI-Dateien an das Unternehmen übermittelt, um ein Deep-Learning (DL)-Modell zu entwickeln. Die NDPI-Dateien wurden in die HSA KIT Software geladen.
- Beginnen Sie, indem Sie auf das Plus-Symbol mit der Beschriftung „Neues Projekt hinzufügen“ klicken.
- Wählen Sie dann die Option „Annotator“.
- Wählen Sie anschließend die spezifische NDPI-Datei aus, die Sie annotieren möchten.
- Der nächste Schritt beinhaltet die Auswahl der Basis oder des Interessensgebiets (ROI) zum Erstellen von GTD für das Projekt, das annotiert werden soll.
- Im nächsten Schritt werden zwei verschiedene Projekte annotiert: „Myokard“ und „Kardiomyozyten“. Die Annotation des „Myokards“ umfasst die Markierung eines größeren Bereichs zur Annotation, während bei „Kardiomyozyten“ bestimmte Zelltypen, nämlich „Transversale“ und „Longitudinale“ Zellen, identifiziert und analysiert werden.
Dieser umfassende Prozess ermöglichte die Entwicklung eines DL-Modells zur Analyse von Herzgewebe, was zum Verständnis und zur Entwicklung von Herzerkrankungen beiträgt. Die Erstellung hochwertiger Ground Truth Daten spielte eine entscheidende Rolle bei der Schulung und Validierung des Modells für genaue und zuverlässige Ergebnisse.
Für das Trainingsverfahren innerhalb von HSA KIT ist es entscheidend, dass …
4-Wählen Sie mögliche Transformationen (Augmentation): Während des Trainings von maschinellen Lernmodellen, insbesondere von Deep-Learning-Modellen für die Bildklassifizierung oder Objekterkennung, ist die Datenaugmentation eine weit verbreitete Methode, um die Vielfalt im Trainingsdatensatz zu erhöhen und die Generalisierungsfähigkeit des Modells zu verbessern.

5-Meta-Daten: Die Option, entweder ein neues Modell zu trainieren oder mit einem bestehenden zu beginnen: „Starten Sie von vorne, indem Sie den Namen für das neue Modell eingeben“. „Verwenden Sie ein bestehendes Modell, indem Sie den gewünschten Modellnamen und die Version auswählen“.

6-Erweiterte Einstellungen: Die Auswahl der erweiterten Einstellungen bezieht sich normalerweise auf Konfigurationsoptionen und Parameter, die während des Trainings von maschinellen Lern- oder Deep-Learning-Modellen anpassbar sind. Diese Optionen bieten eine höhere Präzision bei der Steuerung des Trainingsprozesses und können sich auf die Leistung des Modells auswirken.
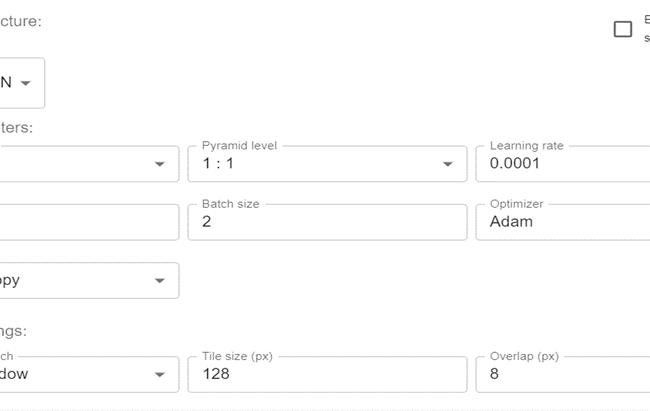
1-Um den Trainingsprozess zu starten, wählen Sie „Modell trainieren“ und erstellen dann ein neues Modell, indem Sie auf „Benutzerdefiniertes KI-Modell trainieren“ klicken.

2-Modelltyp auswählen: Die Entwicklung von KI-Systemen in einer Vielzahl von Anwendungen und Bereichen basiert auf diesen Modelltrainingstypen, die es Maschinen ermöglichen, aus Daten zu lernen und gültige Ergebnisse zu erzielen. Die zu verwendende Trainingsmethode hängt von der vorliegenden Aufgabe und der Verfügbarkeit beschrifteter Daten ab.

3-Struktur auswählen: Die Auswahl der Struktur für den Trainingsprozess beinhaltet die Entscheidung über den architektonischen Rahmen, der verwendet wird, um das KI-Modell zu entwickeln und zu trainieren.

Workflow mit HSA KIT
Die Analyse von Proben und das Digitalisieren von Objektträgern war noch nie einfacher. HSA KIT bietet ein unvergleichliches Erlebnis für seine Kunden, die fortschrittlichere Alternativen annehmen und ihre Workflow-Effizienz verbessern möchten. Das HSA-Team geht weit, um seine Kunden zufrieden zu stellen, unterstützt bei der Softwareinstallation, Integration und bietet kontinuierliche Unterstützung und Updates.
Mit der KI-basierten Analyse von HSA KIT können Sie erwarten:
- Standardisierte Prozesse, die sowohl subjektive als auch objektive Analysen umfassen.
- Extraktion relevanter Merkmale aus Rohdaten, um aussagekräftige Darstellungen für das Training von KI-Modellen zu generieren.
- Modulauswahl und -konfiguration ohne umfangreiche Codierung.
- Benutzerfreundliche Software, die leicht zu erlernen ist und Annotation, Training und Automatisierung ermöglicht.
- Schnelle und effektive Analyse zahlreicher medizinischer Bilder, wodurch die Diagnose- oder Behandlungszeit verkürzt wird.
- Automatisierte Berichtserstellung zur Steigerung der Produktivität und Unterstützung von Ärzten oder Radiologen im Bewertungsprozess.
Metriken
Eine Reihe von Metriken wird verwendet, um die Leistung von Algorithmen zur Interpretation medizinischer Bilder zu bewerten. Die Konfusionsmatrix ist eine Tabelle, die verwendet wird, um die Leistung eines Algorithmus zu visualisieren und mehrere Bewertungsmaße zu berechnen. Konfusionsmatrizen werden verwendet, um Deep-Learning-Modelle zu bewerten und eine genauere Darstellung ihrer Leistung zu bieten. In Deep Learning beziehen sich Metriken auf quantitative Maße, die verwendet werden, um die Leistung eines maschinellen Lernmodells zu bewerten.
Diese Metriken bieten Einblicke, wie gut ein Modell bei einer bestimmten Aufgabe abschneidet, und können Entwicklern und Praktikern helfen, fundierte Entscheidungen bei der Modellauswahl, Optimierung und Feinabstimmung zu treffen. Dieser Artikel zielt darauf ab, die Definition von häufig verwendeten Metriken im maschinellen Lernen kurz zu erläutern, einschließlich Accuracy, Precision, Recall, und F1.
Accuracy misst die Gesamtgenauigkeit der Modellleistung.

Precision gibt an, wie viele vorhergesagte Positive von allen vorhergesagten Positiven tatsächlich Positive sind.

Recall misst, wie viele Positive das Modell korrekt vorhergesagt hat, von allen tatsächlichen Positiven.

F1 ist der harmonische Mittelwert von Precision und Recall.