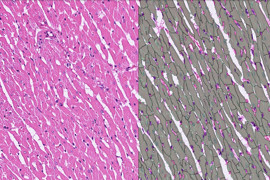
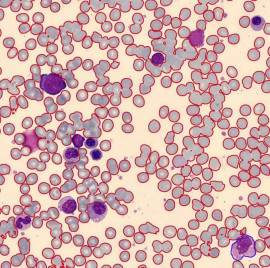
Einführung
Die Leber ist ein lebenswichtiges Organ im menschlichen Körper und spielt eine entscheidende Rolle bei verschiedenen Funktionen, die zum Stoffwechsel, zur Immunität, zur Verdauung, zur Entgiftung und zur Speicherung von Vitaminen beitragen. Sie macht etwa 2% des Gesamtgewichts eines Erwachsenen aus. Eine der einzigartigen Eigenschaften der Leber ist ihre doppelte Blutversorgung, die aus zwei Quellen stammt: Die Pfortader liefert etwa 75% des Blutes, während die Leberarterie die restlichen 25% bereitstellt. Die Leber besteht aus vier Lappen: dem größeren rechten und linken Lappen sowie dem kleineren Schwanzlappen und quadratischen Lappen. Der linke und rechte Lappen sind durch das falciforme („sichelförmige“ auf Lateinisch) Band getrennt, das die Leber mit der Bauchwand verbindet. Die Lappen der Leber können weiter in acht Segmente unterteilt werden, die aus Tausenden von Läppchen (kleine Lappen) bestehen. Jedes dieser Läppchen hat einen Gang, der zur gemeinsamen Lebergang führt, welcher die Galle aus der Leber ableitet.

HSA KIT
Die HSA KIT-Software bietet eine intuitive Benutzeroberfläche zusammen mit fortschrittlichen professionellen Annotationsfunktionen, die Präzision bis ins kleinste Pixel gewährleisten. Durch Prozessstandardisierung, Konsistenzwahrung und Unterstützung der Reproduzierbarkeit wird der gesamte Analyseprozess erheblich verbessert.
Das Lebermodell konzentriert sich auf die Erkennung der zwei wichtigsten Strukturen für die Untersuchung des Leberorgans:
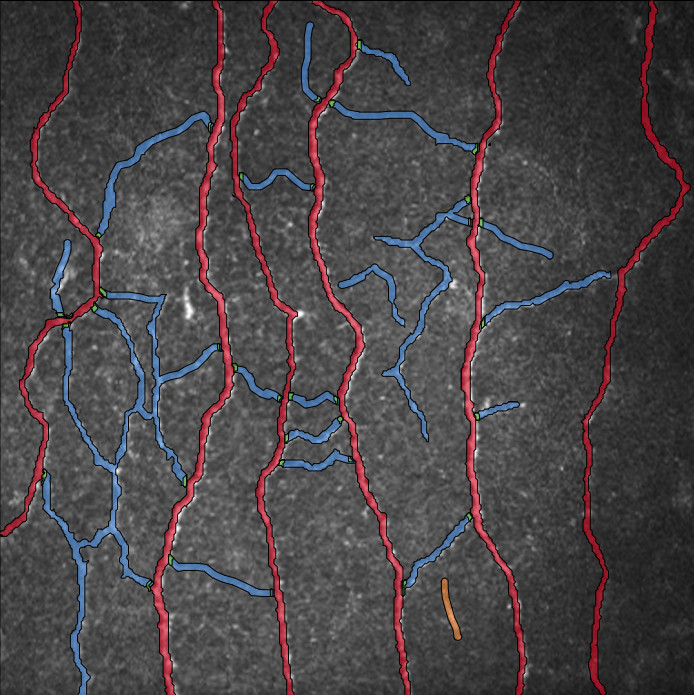
- Gefäße: Im Kontext eines Leberprojekts bezieht sich „Gefäße“ typischerweise auf Blutgefäße innerhalb der Leber. Blutgefäße spielen eine entscheidende Rolle beim Transport von Blut durch die Leber, und ihre Analyse kann Einblicke in die Gesundheit und Funktion des Organs geben. Die Annotation von Gefäßen in Leberbildern kann helfen, deren Verteilung, Struktur und potenzielle Anomalien zu identifizieren und so zu diagnostischen und Forschungszwecken beitragen.
- Nicht-Gefäße: Bezieht sich auf Bereiche innerhalb der Leberbilder, die nicht Teil des Blutgefäßnetzes sind. Dazu können verschiedene Gewebe, Organe, Strukturen oder sogar Artefakte gehören, die in den Bildern vorhanden sind, aber nicht zu den Blutgefäßen gehören.
Verkleinerte Ansicht


Vergrößerte Ansicht – Negative Zellen


Vergrößerte Ansicht – Positive Zellen


Vergrößerte Ansicht – Unklare Zellen


Funktionen der Leber
Die Leber erfüllt mehrere lebenswichtige Funktionen, darunter:
- Entgiftung: Die Leber filtert Giftstoffe und schädliche Substanzen aus dem Blut. Sie entfernt Verbindungen aus dem Körper, einschließlich Hormone wie Östrogen und Aldosteron, sowie Verbindungen von außerhalb des Körpers, einschließlich Alkohol und anderen Drogen.
- Gallenproduktion: Die Leber produziert Galle, eine Flüssigkeit, die dem Körper hilft, Nahrung zu verdauen. Galle besteht aus Gallensalzen, Cholesterin, Bilirubin, Elektrolyten und Wasser.
- Stoffwechsel: Die Leber metabolisiert Proteine, Kohlenhydrate und Fette, sodass der Körper sie nutzen kann. Sie spielt auch eine Rolle beim Abbau von Häm zu unkonjugiertem Bilirubin und konjugiert es.
- Blutregulation: Die Leber reguliert die meisten chemischen Spiegel im Blut. Sie speichert Eisen und Kupfer und spielt eine Rolle in der Hämatologie mit der Synthese von Gerinnungsfaktoren und Proteinen. Die Leber reguliert auch den Blutzuckerspiegel und produziert Substanzen, die helfen, das Blut zu gerinnen.

Die häufigsten Lebererkrankungen
Hepatitis ist ein Überbegriff, der sich auf die Entzündung der Leber bezieht. Diese Entzündung kann durch verschiedene Faktoren verursacht werden, einschließlich Virusinfektionen (virale Hepatitis), Kontakt mit bestimmten Chemikalien oder Drogen, übermäßigen Alkoholkonsum, spezifische genetische Störungen oder eine Autoimmunreaktion, bei der das Immunsystem fälschlicherweise die Leber angreift und zu Autoimmunhepatitis führt.
1- Hepatitis A: Dieses hoch ansteckende Virus wird hauptsächlich durch kontaminierte Lebensmittel oder Wasser übertragen. Es handelt sich um eine akute, kurzfristige Form der Hepatitis, die in der Regel keine Behandlung erfordert, da sie von selbst abklingt und keine langfristigen Auswirkungen hat.
2- Hepatitis B: Die Infektion erfolgt durch die Übertragung von Körperflüssigkeiten wie Blut und Sperma. Sie kann eine akute (kurzfristige) oder chronische (langfristige) Infektion verursachen. Oft benötigen akute Infektionen keine Behandlung und bessern sich von selbst. Einige chronische Infektionen erfordern eine Behandlung, um die Schwere der Symptome zu lindern.
Fettleberkrankheit: ist eine Erkrankung, bei der sich zu viel Fett in der Leber ansammelt. Es gibt zwei Haupttypen:
- Nichtalkoholische Fettlebererkrankung (NAFLD):
- NAFLD ist nicht mit starkem Alkoholkonsum verbunden.
- Im Frühstadium wird sie als einfache Fettleber bezeichnet, gekennzeichnet durch Fettansammlung ohne Entzündung oder Leberschädigung.
- Wenn Entzündungen und Leberschäden auftreten, entwickelt sich die nichtalkoholische Steatohepatitis (NASH), die zu Leberfibrose oder Narbenbildung (Zirrhose) führen kann.
Leberkrebs: Krebs wird allgemein als eine Krankheit beschrieben, bei der sich abnormale Zellen zu schnell vermehren und den normalen Zellen weniger Raum lassen. Es gibt zwei Arten von Leberkrebs, primären und sekundären.
Digitalisierung von Slides
Der Prozess der Digitalisierung von Slides wird durch die Nutzung der Software HSA SCAN, einer Entwicklung der HS Analysis GmbH, durchgeführt. HSA SCAN dient dem Zweck, physische Slides in digitale Dateien zu verwandeln. Darüber hinaus umfasst das Verfahren die Nutzung des HSA SCANNERS, einem Hardware-Produkt, das entwickelt wurde, um ein analoges Mikroskop wirtschaftlich in ein digitales umzuwandeln.

Der erste Schritt besteht darin, das Mikroskop einzuschalten und dann das Slide darunter zu platzieren, wobei das entsprechende Objektiv eingestellt wird.

Der zweite Schritt besteht darin, die Computereinstellungen so anzupassen, dass der Scan angezeigt wird.

Der nächste Schritt besteht darin, den Scanvorgang für das Slide zu starten, bis jeder Teil des Scans abgeschlossen ist.

HSA vereinfacht den Prozess, indem es die Abmessungen des Mikroskops und alle erforderlichen Spezifikationen anfordert. Nach der Bereitstellung werden ein passgenauer Ständer und ein auf das Mikroskop abgestimmter Motor geliefert. Dies eliminiert die Notwendigkeit manueller Anpassungen und garantiert konsistente Ergebnisse.
Die Vorteile umfassen:
- Präzises und schnelles Scannen: Erzielung von genauen und schnellen Scans.
- Kostengünstig: Bietet Kostenvorteile im Vergleich zu automatisierten Scannern.
- Zeitersparnis: Automatisiert Aufgaben, die traditionell manuelle Eingriffe erforderten.
- Verbesserter Arbeitsablauf und Qualität: Reduziert die Wahrscheinlichkeit von Fehlern oder Inkonsistenzen.
- Intuitive Steuerung: Benutzerfreundliche Oberfläche, auch für Personen mit begrenzter Mikroskop-Erfahrung zugänglich.
Stochastischer Gradientenabstieg (SGD)
Der Begriff „stochastisch“ bezieht sich auf ein System oder einen Prozess, der mit zufälligen Wahrscheinlichkeiten verbunden ist. Der stochastische Gradientenabstieg nutzt dieses Konzept, um den Gradientenabstieg-Prozess zu beschleunigen. Im Gegensatz zum standardmäßigen Gradientenabstieg (SGD), bei dem der gesamte Datensatz in jeder Iteration verwendet wird, nutzt der stochastische Gradientenabstieg den Kosten-Gradienten nur eines Beispiels pro Iteration.[41]
Die drei Haupttypen des Gradientenabstiegs sind Batch-Gradientenabstieg, stochastischer Gradientenabstieg und Mini-Batch-Gradientenabstieg. Die Wahl zwischen Batch-Gradientenabstieg, stochastischem Gradientenabstieg und Mini-Batch-Gradientenabstieg hängt von der Größe des Datensatzes, den verfügbaren Rechenressourcen und dem vorliegenden Optimierungsproblem ab. Der stochastische Gradientenabstieg (SGD) zeichnet sich durch seine Recheneffizienz aus, insbesondere bei großen Datensätzen. Im Gegensatz zum traditionellen Gradientenabstieg, der die Verarbeitung des gesamten Datensatzes erfordert, verarbeitet SGD nur einen Datenpunkt oder eine kleine Charge pro Iteration. Dies reduziert die Rechenkosten erheblich und beschleunigt die Konvergenz. Finden Sie die optimalen Werte der Parameter eines Modells, die eine Kostenfunktion minimieren.
Encoder-Decoder-Struktur
Ein Encoder-Decoder-Modell im Maschinenlernen ist eine Art von neuronaler Netzwerkarchitektur, die eine Eingabesequenz verarbeitet und in eine festgelegte interne Darstellung umwandelt, die als Kontextvektor bezeichnet wird. Dieser wird dann an einen Decoder übergeben, der eine Ausgabesequenz erzeugt.
Die Encoder-Decoder-Architektur findet breite Anwendung in der Bildverarbeitung, insbesondere bei Aufgaben wie der Bildsegmentierung. In diesem Szenario nimmt sie ein Bild als Eingabe und erzeugt ein segmentiertes Bild als Ausgabe. Diese Architektur verwendet im Wesentlichen ein tiefes konvolutionales neuronales Netzwerk, um diese Transformation zu erreichen.

Es gibt mehrere Vorteile bei der Implementierung einer Encoder-Decoder-Architektur mit Recurrent Neural Networks (RNNs):
- Flexibilität: Encoder-Decoder-RNNs können für verschiedene Aufgaben verwendet werden, wie maschinelle Übersetzung, Textzusammenfassung und Bildbeschriftung.
- Verarbeitung von Eingaben und Ausgaben variabler Länge: Encoder-Decoder-RNNs sind besonders nützlich für Aufgaben mit unterschiedlich langen Eingabe- und Ausgabesequenzen.
- Verarbeitung sequentieller Daten: RNNs sind besonders gut geeignet für die Verarbeitung sequentieller Daten.
- Umgang mit fehlenden Daten: Encoder-Decoder-RNNs können fehlende Daten verarbeiten, indem sie nur die verfügbaren Daten an den Encoder weitergeben.
Daher ermöglicht die Encoder-Decoder-Struktur, die meisten Informationen aus einem Bild zu extrahieren und wertvolle Korrelationen zwischen verschiedenen Eingaben innerhalb des Netzwerks zu generieren.
Digitale Darstellung von Bildern
Ein digitales Bild ist eine Darstellung eines realen Bildes als eine Reihe von Zahlen, die von einem digitalen Computer gespeichert und verarbeitet werden können. Um das Bild in Zahlen zu übersetzen, wird es in kleine Bereiche unterteilt, die als Pixel (Bildelemente) bezeichnet werden. Für jedes Pixel zeichnet das Bildgebungsgerät eine Zahl oder eine kleine Menge von Zahlen auf, die eine Eigenschaft dieses Pixels beschreiben, wie seine Helligkeit (die Intensität des Lichts) oder seine Farbe. Die Zahlen sind in einem Array von Reihen und Spalten angeordnet, das den vertikalen und horizontalen Positionen der Pixel im Bild entspricht.
Die digitale Darstellung von Bildern ist ein wichtiges Werkzeug bei der Erkennung und Analyse von Lebererkrankungen. Hier sind einige Beispiele, wie die digitale Bildanalyse in der Forschung zu Lebererkrankungen verwendet wurde:
Deep Learning bei Lebererkrankungen: Bewertung der Leistung von Deep-Learning-Algorithmen bei der Erkennung von Leberkrebs bei Hepatitis-Patienten
Mean Average Precision (mAP)
Mean Average Precision (mAP) ist eine weit verbreitete Metrik zur Bewertung von Maschinenlernmodellen. mAP spielt eine entscheidende Rolle bei Benchmark-Herausforderungen wie PASCAL VOC, COCO und anderen. Es misst die Gesamtleistung eines Modells über verschiedene Kategorien hinweg und bietet eine ausgewogene Sicht auf dessen Genauigkeit. Durch die Durchschnittsbildung der Average Precision-Werte für jede Klasse bietet mAP ein umfassendes Verständnis der Fähigkeit eines Modells, verschiedene Kategorien effektiv zu behandeln.[62]
Die mAP-Formel basiert auf folgenden Teilmetriken:
- Konfusionsmatrix,
- Intersection over Union (IoU),
- Recall,
- Präzision
Präzision ist das Verhältnis von korrekt vorhergesagten Positiven zu den vorhergesagten Positiven. Genauer gesagt zeigt die Präzision, wie viele der als positiv klassifizierten Objekte zur positiven Klasse gehören.
Hier sind die Schritte zur Berechnung der AP:
- Erzeuge die Vorhersagewerte mithilfe des Modells.
- Wandle die Vorhersagewerte in Klassenbezeichnungen um.
- Berechne die TP-, FP-, TN- und FN-Konfusionsmatrizen.
- Bestimme die Präzisions- und Recall-Metrik.
- Bestimme die Fläche unter der Präzisions-Recall-Kurve.
Berechne die durchschnittliche Präzision
Workflow with HSA KIT
Die Analyse von Proben und das Digitalisieren von Folien war noch nie so mühelos. HSA KIT bietet seinen Kunden, die fortschrittlichere Alternativen anstreben und ihre Workflow-Effizienz verbessern möchten, ein unvergleichliches Erlebnis. Das HSA-Team geht große Wege, um seine Kunden zufriedenzustellen, indem es bei der Softwareinstallation, Integration hilft und kontinuierliche Unterstützung sowie Updates bereitstellt.
Mit der KI-gestützten Analyse von HSA KIT können Sie Folgendes erwarten:
- Standardisierte Prozesse, die sowohl subjektive als auch objektive Analysen umfassen.
- Extraktion relevanter Merkmale aus Rohdaten zur Erstellung bedeutungsvoller Repräsentationen für das Training von KI-Modellen.
- Modulauswahl und -konfiguration ohne umfangreiche Programmierung.
- Benutzerfreundliche Software, die leicht zu erlernen ist und Annotation, Training und Automatisierung ermöglicht.
- Schnelle und effektive Analyse zahlreicher medizinischer Bilder, wodurch Diagnose- oder Behandlungszeiten verkürzt werden.
- Automatisierte Berichtserstellung zur Steigerung der Produktivität und Unterstützung von Ärzten oder Radiologen im Bewertungsprozess.

Merkmalextraktion
Merkmalextraktion ist ein Prozess, bei dem Rohdaten in numerische Merkmale umgewandelt werden, die verarbeitet werden können, während die Informationen im ursprünglichen Datensatz erhalten bleiben. Es ist ein entscheidender Schritt im Maschinenlernen, in der Mustererkennung und in der Bildverarbeitung.
Die Merkmalextraktion ist ein wichtiger Schritt in der Datenanalyse und im Maschinenlernen, der eine effizientere und effektivere Verarbeitung großer Datensätze ermöglicht.
Merkmalextraktion ist besonders nützlich beim Arbeiten mit großen Datenmengen im Maschinenlernen, wo es eine mühsame Aufgabe sein kann, alle Eingabedaten zu verarbeiten. Durch die Zusammenfassung der ursprünglichen Merkmale in eine kleinere Menge bedeutungsvoller Gruppen hilft die Merkmalextraktion, die benötigte Zeit und den Speicherplatz für die Datenverarbeitung zu reduzieren.

Deep learning (DL)
Künstliche Intelligenz (KI) und maschinelle Lerntechniken, die als Deep Learning bezeichnet werden, modellieren, wie Menschen spezifische Arten von Informationen erwerben. Deep-Learning-Modelle können angewiesen werden, Klassifikationsaufgaben durchzuführen und Muster in Bildern, Texten, Audios und anderen Datentypen zu erkennen. Darüber hinaus wird es verwendet, um Aufgaben zu automatisieren, die normalerweise menschliche Intelligenz erfordern, wie zum Beispiel das Annotieren von Bildern oder das Transkribieren von Audiodateien.
Maschinelles Lernen (ML) ist ein Teilbereich der KI, bei dem Algorithmen trainiert werden, Aufgaben durch Merkmalslernen anstelle eines expliziten regelbasierten Ansatzes zu lösen. Wenn ein „Training“-Kohorte bereitgestellt wird, identifiziert der Algorithmus relevante Merkmale, die anschließend zur Vorhersage verwendet werden. Daher „lernt“ die „Maschine“ aus den Daten selbst.
Deep Learning ist ein wichtiger Bestandteil der Datenwissenschaft, einschließlich der Statistik. Es ist äußerst vorteilhaft für Datenwissenschaftler, die mit der Sammlung, Analyse und Interpretation großer Datenmengen beauftragt sind; Deep Learning beschleunigt und erleichtert diesen Prozess. [5] Maschinelles Lernen und Deep Learning sind beide Teilbereiche der künstlichen Intelligenz (KI) und werden verwendet, um Computersysteme zu trainieren, Aufgaben auszuführen, ohne explizit programmiert zu werden. Es gibt jedoch einige Unterschiede zwischen den beiden. Maschinelles Lernen ist eine Art der KI, die es Computern ermöglicht, aus Daten mithilfe von Algorithmen zu lernen und eine Aufgabe auszuführen, ohne explizit programmiert zu werden. Es kann überwacht, unbeaufsichtigt oder halbüberwacht sein. Beim überwachten Lernen wird der Algorithmus mit gekennzeichneten Daten trainiert, während beim unbeaufsichtigten Lernen der Algorithmus mit unbeschrifteten Daten trainiert wird.

Regularisierung
Regularisierung umfasst das Einschränken eines Modells, um Überanpassung zu verhindern, indem die Größe der Koeffizientenschätzungen in Richtung Null reduziert wird. Wenn ein Modell mit Überanpassung zu kämpfen hat, ist es wichtig, seine Komplexität zu bändigen. In der Praxis bekämpft die Regularisierung Überanpassung, indem sie einen zusätzlichen Term in die Verlustfunktion des Modells einführt, wodurch im Wesentlichen eine Strafe verhängt wird.
Overfitting and underfitting are common problems in machine learning that can harm a model’s accuracy. Overfitting occurs when a model learns from noise instead of real patterns in data. Underfitting happens when a model is too simple to grasp the main trends in the data. Underfitting is linked to high bias and low variance, often caused by a model’s simplicity or insufficient data. Remedies involve increasing model complexity, adding pertinent features, minimizing data noise, and extending training duration. Overfitting is tied to high variance and low bias, often driven by model complexity or limited data. Solutions encompass expanding the training dataset, reducing model complexity, early stopping, Ridge, and Lasso regularization, and incorporating dropout in neural networks.

Bias: bezieht sich auf die Annahmen, die ein Modell trifft, um das Lernen einer Funktion zu vereinfachen. Es ist die Fehlerrate der Trainingsdaten. Wenn diese Fehlerrate hoch ist, wird dies als hoher Bias bezeichnet, und wenn sie niedrig ist, als niedriger Bias.
Variance: repräsentiert den Unterschied zwischen den Fehlerraten in Trainings- und Testdaten. Wenn dieser Unterschied hoch ist, wird dies als hohe Varianz bezeichnet; wenn er niedrig ist, als niedrige Varianz. Im Allgemeinen streben wir eine niedrige Varianz an, um ein gut generalisiertes Modell sicherzustellen.
Erstellung von Ground-Truth-Daten
Die Proben, die in dieser Arbeit verwendet wurden, wurden von einem Kunden der HS Analysis GmbH vorbereitet. Die Proben wurden aus der Leber eines verstorbenen Mäuserlebers durch Schneiden, Präparieren von Folien, Färben der Zellen und anschließendes Umwandeln der Folien in digitale CZI-Dateien durch Scannen entnommen und schließlich die CZI-Dateien an das Unternehmen gesendet, um ein DL-Modell zu erstellen. Um ein DL-Modell zu erstellen, erfordert die erste Phase der Modellentwicklung die Erstellung eines Ground-Truth-Datensatzes (GTD). Die folgenden Schritte sind erforderlich:
- Die CZI-Dateien wurden in die HSA KIT-Software geladen.
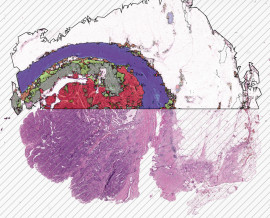
- Ein Bereich zur Erstellung von Ground-Truth-Daten (GTD) wurde ausgewählt, wobei sichergestellt wurde, dass der Bereich nicht am Rand der Probe lag. Dieser Bereich von Interesse wurde dann mit dem Region-of-Interest (ROI)-Werkzeug identifiziert.
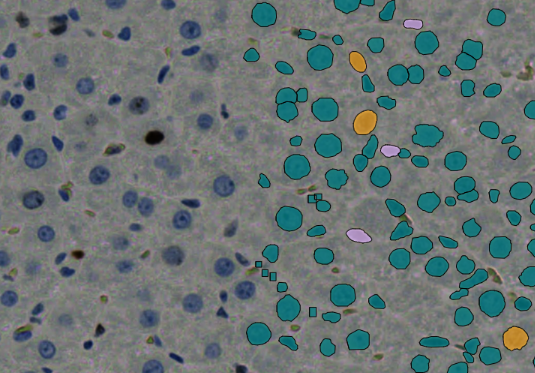
- Der Zielbereich, der sowohl „Gefäße“ als auch „Nicht-Gefäße“ umfasst, wurde innerhalb des ausgewählten ROI-Bereichs annotiert.
- Die Kategorie „Nicht-Gefäße“ wurde weiter in Unterklassen wie „Zell-Positiv“, „Zell-Negativ“ und „Unklare Zelle“ unterteilt.
- Diese annotierten Daten wurden verwendet, um das Deep-Learning (DL)-Modell mit der HSA KIT-Software zu trainieren.
Nachdem die Ground-Truth-Daten (GTD) erstellt wurden, wurde das Modell trainiert (die Ergebnisse werden in Kapitel 4 erklärt). Anschließend wurden zusätzliche GTD erstellt, um die Leistung des Modells zu verbessern. Zunächst wurde das Modell mit 724 GTD trainiert, wobei der Schwerpunkt auf umfassenderen Bereichen wie „Gefäße“ und „Nicht-Gefäße“ lag. Beim zweiten Mal wurde das Modell mit 6.139 GTD (6,1K) trainiert, wobei spezifischere Bereiche wie „Zell-Positiv“, „Zell-Negativ“ und „Unklare Zellen“ angestrebt wurden. Die Verteilung der Klassen und ihre entsprechenden Prozentsätze im Datensatz sind in Tabelle 1 und Tabelle 2 angegeben.
| Anzahl der GTD | Dateinummer | Gefäße | Nicht-Gefäße | |||
| Objekt | Prozentsatz | Objekt | Prozentsatz | |||
| 724 | 1. Datei | 292 | % | 14 | % | |
| 2. Datei | 402 | % | 16 | % | ||
Tabelle 1: Die Anzahl der Gefäße & Nicht-Gefäße, die in dieser Arbeit verwendet wurden
| Anzahl der GTD | Dateinummer | Zell-Positiv | Zell-Negativ | Unklare Zellen | ||||
| Objekt | Prozentsatz | Objekt | Prozentsatz | Objekt | Prozentsatz | |||
| 6,1K | 1. Datei | 345 | % | 5459 | % | 335 | % | |
Tabelle 2: Die Anzahl der Unterzellen, die in dieser Arbeit verwendet wurden.
„Ground Truth“ ist ein Begriff, der häufig in der Statistik und im maschinellen Lernen verwendet wird. Er bezieht sich auf die korrekte oder „wahre“ Antwort auf ein spezifisches Problem oder eine Frage. Es ist ein „Goldstandard“, der verwendet werden kann, um Modell Ergebnisse zu vergleichen und zu bewerten.
Warum ist Ground Truth im Maschinenlernen wichtig?
~ Ground Truth-Daten sind entscheidend für das Modelltraining und die -testung in der KI-Entwicklung. Sie helfen dem Algorithmus, während des Trainings zu lernen und sich zu verbessern, und bieten einen zuverlässigen Maßstab, um die Genauigkeit während des Tests zu bewerten.
~ Während des Modelltrainings werden Ground Truth-Daten verwendet, um dem Algorithmus beizubringen, welche Merkmale und Lösungen für die spezifische Anwendung geeignet sind. Während der Modelltestung wird der trainierte Algorithmus mit Ground Truth-Daten auf die Modellgenauigkeit getestet.
Die GTD-Tabelle bietet einen strukturierten Überblick über die Annotationen und deren Zuordnung zu verschiedenen Dateien, Klassen und Projekten, hauptsächlich im Kontext der Leberanalyse. Diese Daten sollen Einblicke in die Verteilung der Annotationen über verschiedene Kategorien hinweg geben.
Für jede Datei liefert die Tabelle Informationen über die relevante Klasse und das Projekt, auf die sich die Annotationen beziehen. Die Hauptklasse wird angegeben, die in diesem Fall die Klassen „Gefäß“ und „Nicht-Gefäß“ umfasst. Das Hauptprojekt ist „Leber“.
Um festzustellen, ob die Daten ausgewogen sind oder nicht, müssen wir die Verteilung der Annotationen über Klassen und Projekte hinweg betrachten. Aus den oben genannten Informationen scheint es, dass die Annotationen nicht gleichmäßig über Klassen und Projekte verteilt sind. Einige Klassen haben eine signifikant höhere Anzahl an Annotationen als andere. Zum Beispiel hat die Klasse „Zellen blau“ in mehreren Fällen eine viel höhere Anzahl von Annotationen im Vergleich zur Klasse „Zellen braun“.
Human-Machine Interaction (HMI)
Das Annotationstool wird verwendet, um die Ground-Truth-Daten (GTD) zu erstellen und zu klassifizieren, die in der Regel aus Hunderten bis Tausenden von Daten bestehen. Die Qualität der generierten Daten ist entscheidend für die Genauigkeit der Segmentierung, und die Qualität des DL-Modells kann nur so gut sein wie die Qualität der GTD. Die HSA KIT-Software ist darauf ausgelegt, sich nahtlos in bestehende Laborinformationssysteme zu integrieren, was einen reibungslosen Datenaustausch und Präzision durch Mensch-Maschine-Interaktion (HMI) ermöglicht. Das bedeutet, dass bei Unzufriedenheit jederzeit Anpassungen vorgenommen werden können.
Titel: Annotation von Leberprojekten mit HSA KIT: Präzision und Effizienz
“HSA KIT” software—a powerful solution designed to elevate annotation precision and analysis efficiency. With its user-friendly interface and advanced annotation features, it ensures meticulous detail down to the pixel level. By standardizing processes, maintaining consistency, and supporting reproducibility, HSA KIT transforms analysis workflows. Within the Liver Model, it focuses on the essential structures for liver study: “Vessels” encompassing blood vessels crucial for circulation, and “Non-Vessels” representing diverse liver components. Additionally, the “Cell Class” feature distinguishes between “Positive” and “Negative” cells, enhancing the depth of analysis.