
Überblick über die vielfältigen Funktionen des Prionproteins bei der Creutzfeldt-Jakob-Krankheit, der Alzheimer-Krankheit und anderen Demenzerkrankungen. Das Prionprotein dient als Co-Rezeptor für neurotoxische oligomere Spezies wie Beta-Amyloid und α-Synuclein und vermittelt die Neurotoxizität über die Src-Kinase Fyn. Das Prionprotein ist über LRP an der Verbreitung von Tau-Oligomeren beteiligt. Das Prionprotein ist auch an der Übertragung der durch pathologische Prionen (PrPSc) verursachten Neurotoxizität beteiligt.
HSA KIT: Präzise Analyse von Vakuolen und PrP-Depositen mit Deep Learning
Vakuole
Im Verlauf neurodegenerativer Erkrankungen schwellen Nervenzellen, die mit fehlgefalteten Prionproteinen überladen sind, an und sterben ab. Dadurch entstehen charakteristische Löcher im Gehirngewebe, die wir in histologischen Präparaten erkennen. Diese Vakuolen unterscheiden sich je nach Subtyp in ihrer Größe – von klein über mittel bis hin zu groß oder konfluierend – und variieren zudem zwischen den verschiedenen Gehirnregionen.



PrP (Prion-Protein)
Das speziell entwickelte PrP-Modell ermöglicht die präzise Visualisierung fehlgefalteter Proteine. Mithilfe einer gezielten immunhistochemischen Färbung erscheinen sie als deutlich sichtbare braune Flecken auf histologischen Schnitten. Diese Proteine variieren je nach Subtyp in ihrer Dichte, Größe, Abgrenzung und Verteilung, abhängig von der jeweiligen Gehirnregion.



Region
Das HSA KIT ermöglicht eine genaue Erkennung der betroffenen Regionen und eine differenzierte Analyse von weißer Substanz und Kortex innerhalb einer einzelnen Probe. Zusätzlich werden spezifische Eigenschaften einzelner Gehirnregionen berücksichtigt, wie die Struktur im Thalamus und Striatum oder die unterschiedlichen Schichten im Kleinhirn.



Reingezoomt: Automatische Erkennung des Cerebellums in drei verschiedenen Arealen: Cerebellum Molecular Layer (braun), Cerebellum Granular Layer (lila) und Cerebellum White Matter (blaugrün) mithilfe des HSA KIT.
Automatische Unterteilung des Cortex in 6 Layer mit HSA KIT
Die HSA KIT Software ermöglicht die präzise und automatische Unterteilung des Cortex in sechs Layer, um eine detaillierte Analyse der verschiedenen Zell- und Struktureigenschaften im Gehirn durchzuführen. Diese Methode erfasst und vergleicht spezifische Merkmale wie die Verteilung und Dichte von Strukturen (z. B. Vacuolen oder PrP-Depositen) in den einzelnen Layern.

Rausgezoomt: Automatische Erkennung der Gehirnareale, gefolgt von der automatischen Unterteilung des Cortex in 6 Layer.


Reingezoomt: Automatische Erkennung des Cortical Lobe Cortex (gelb) und des Cortical Lobe White Matter, gefolgt von der Unterteilung des Cortex in 6 Layern. Abschließend wurde mit dem HSA KIT die automatische Erkennung von Vacuolen durchgeführt.
Result-Tabelle
Die Differenzierung von Creutzfeldt-Jakob-Subtypen erfordert eine gründliche Analyse ausgewählter Kennzahlen, die wertvolle Einblicke in die Verteilung und Eigenschaften von Gehirnstrukturen ermöglichen. Diese Kennzahlen sind entscheidend, um Strukturen wie Vakuolen und PrP-Depositen präzise zu untersuchen und aussagekräftige Rückschlüsse auf spezifische Subtypen zu ziehen.
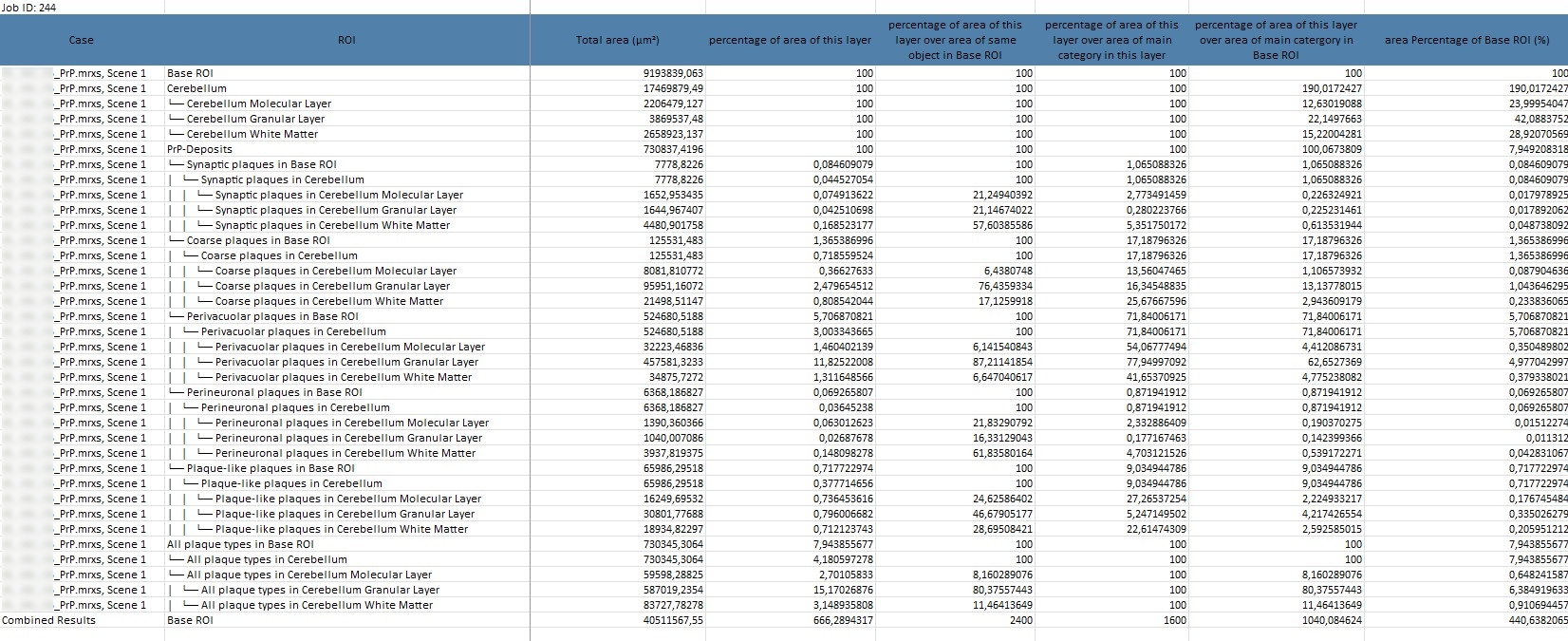
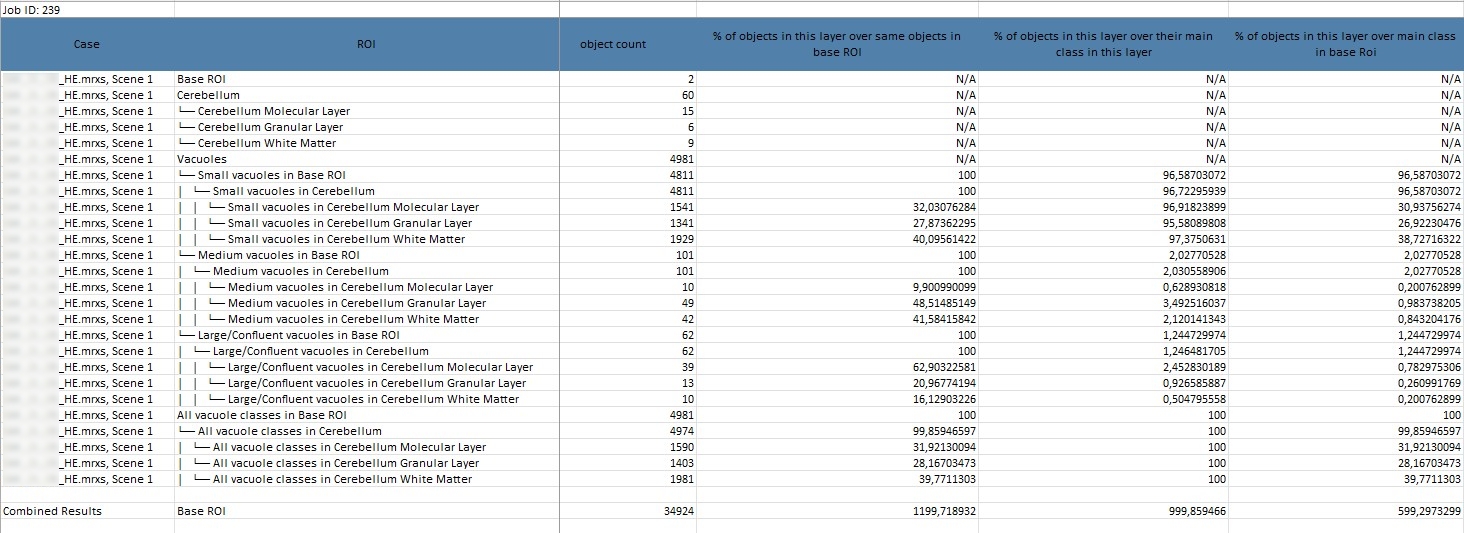
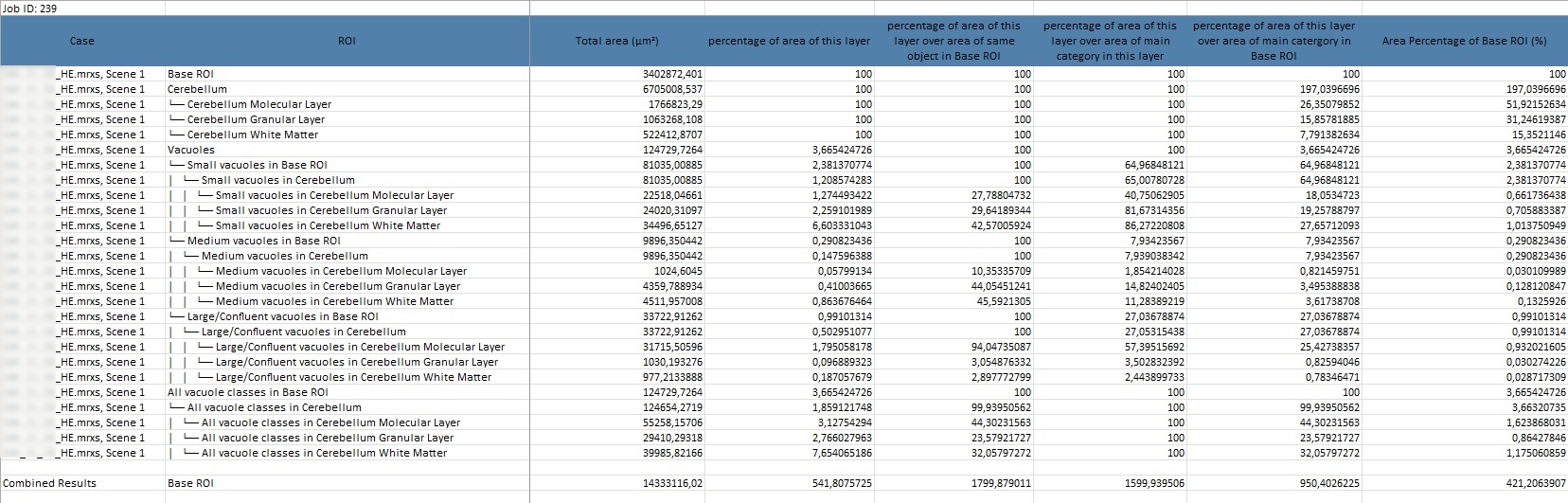
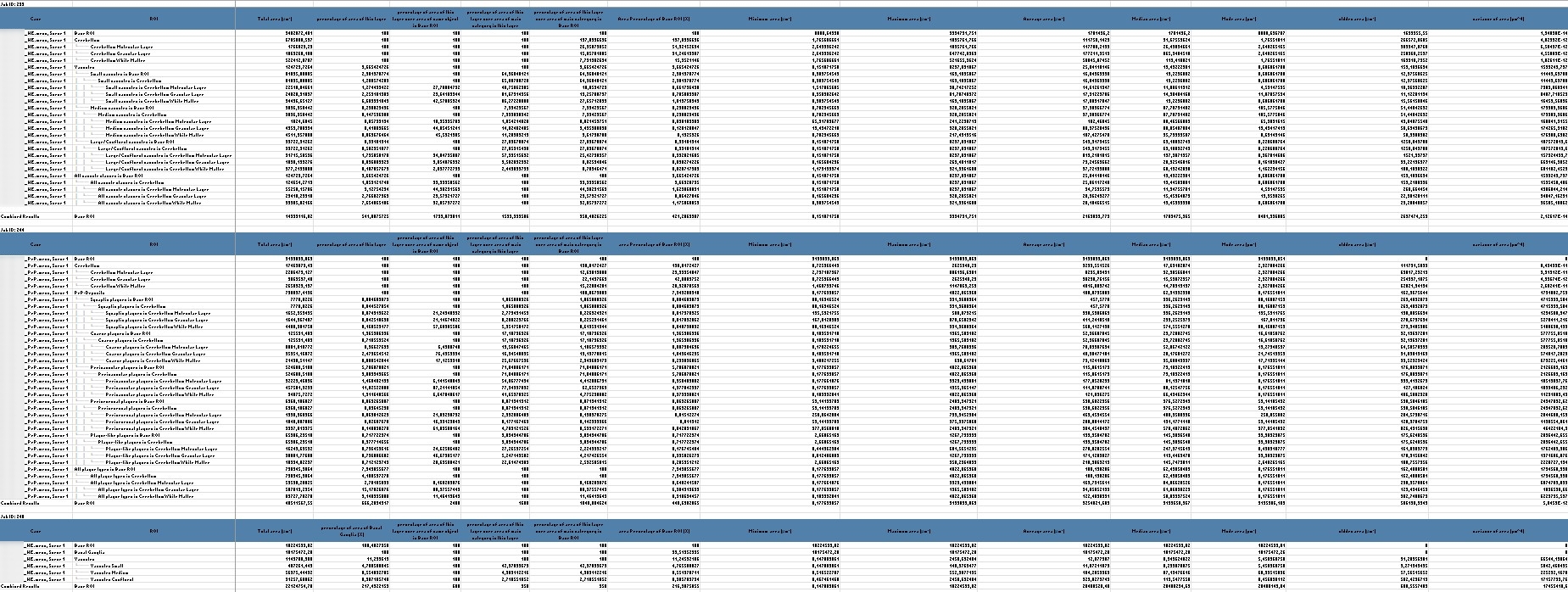
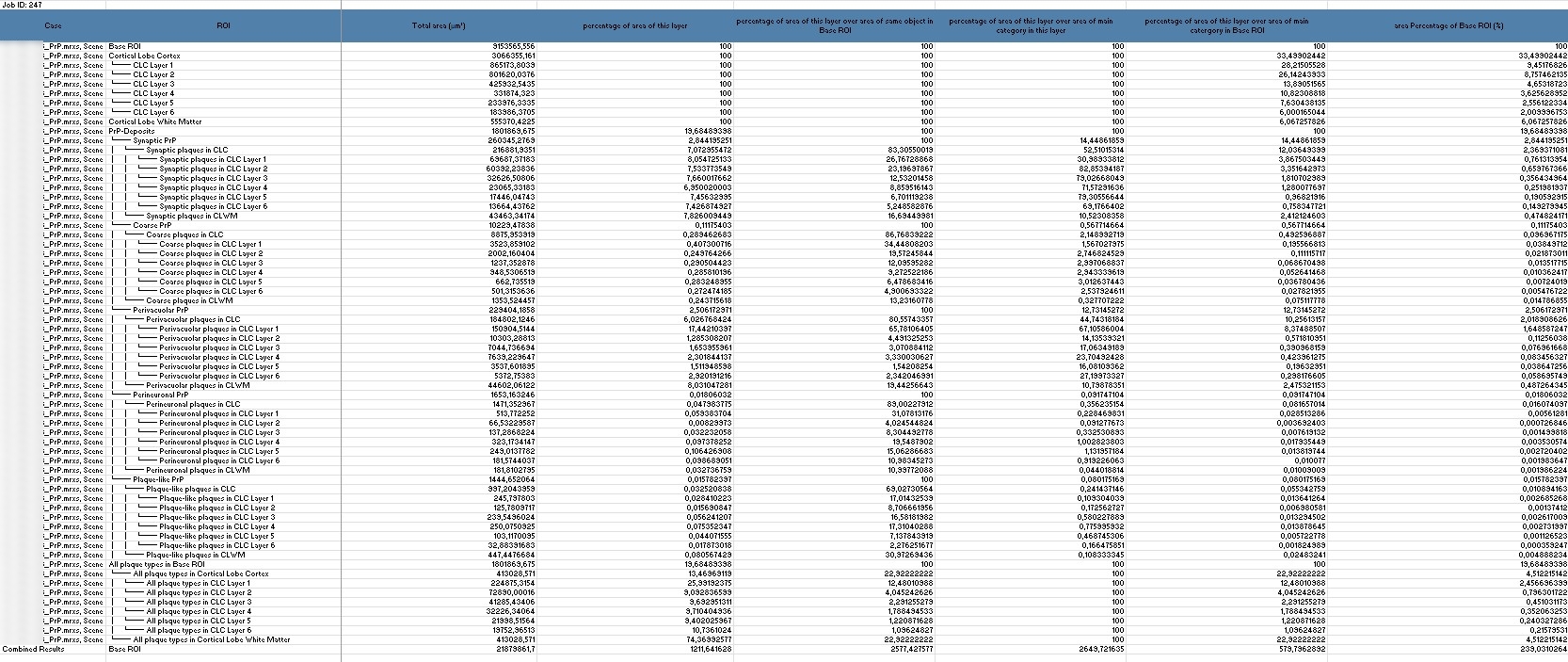
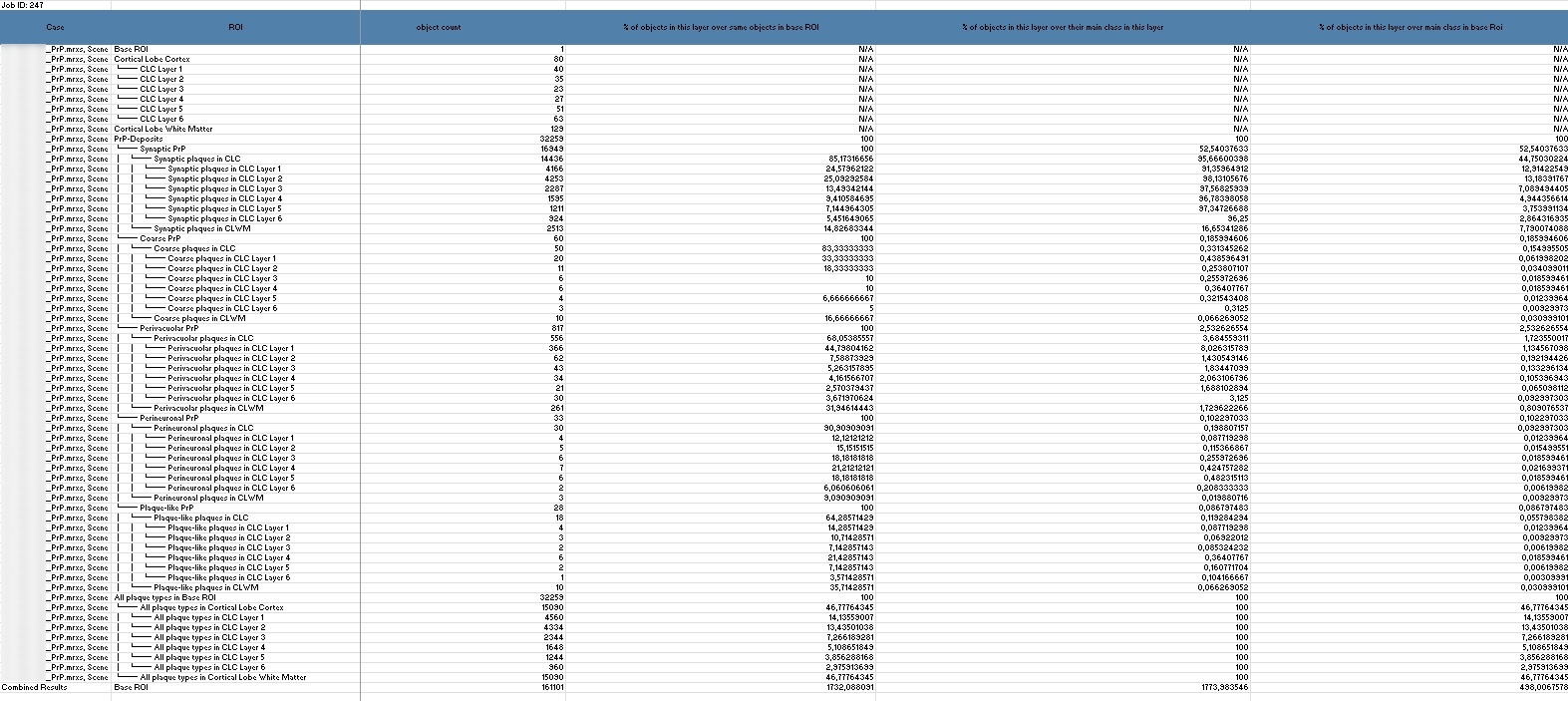
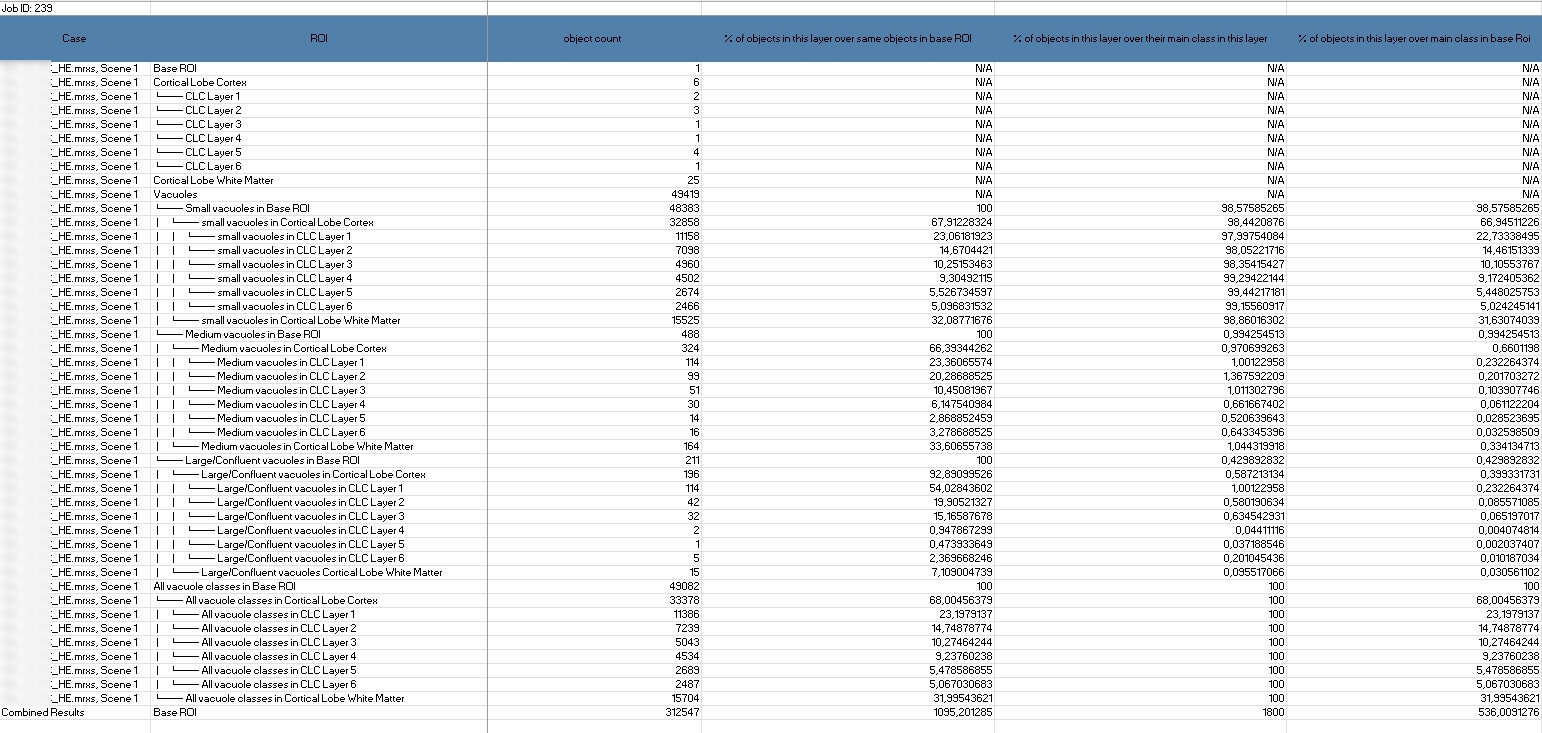
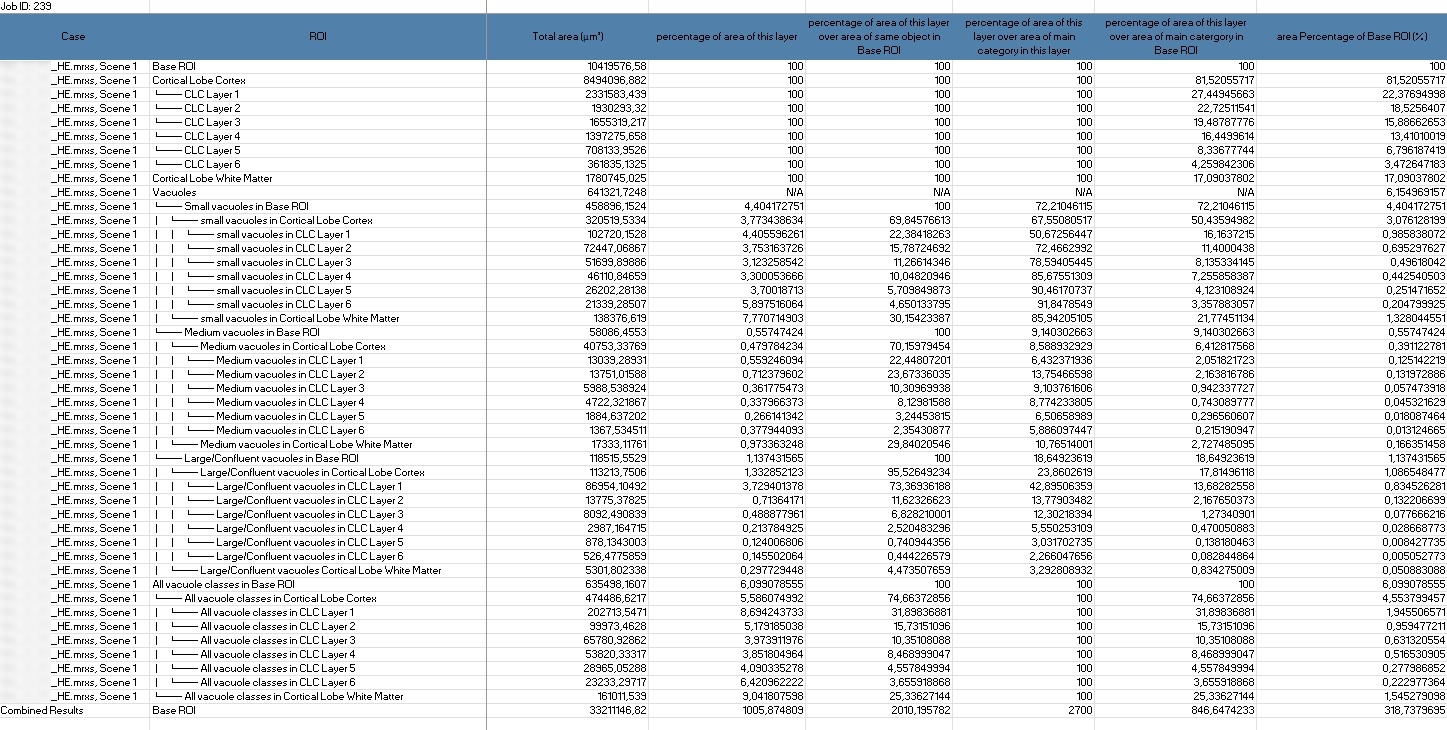
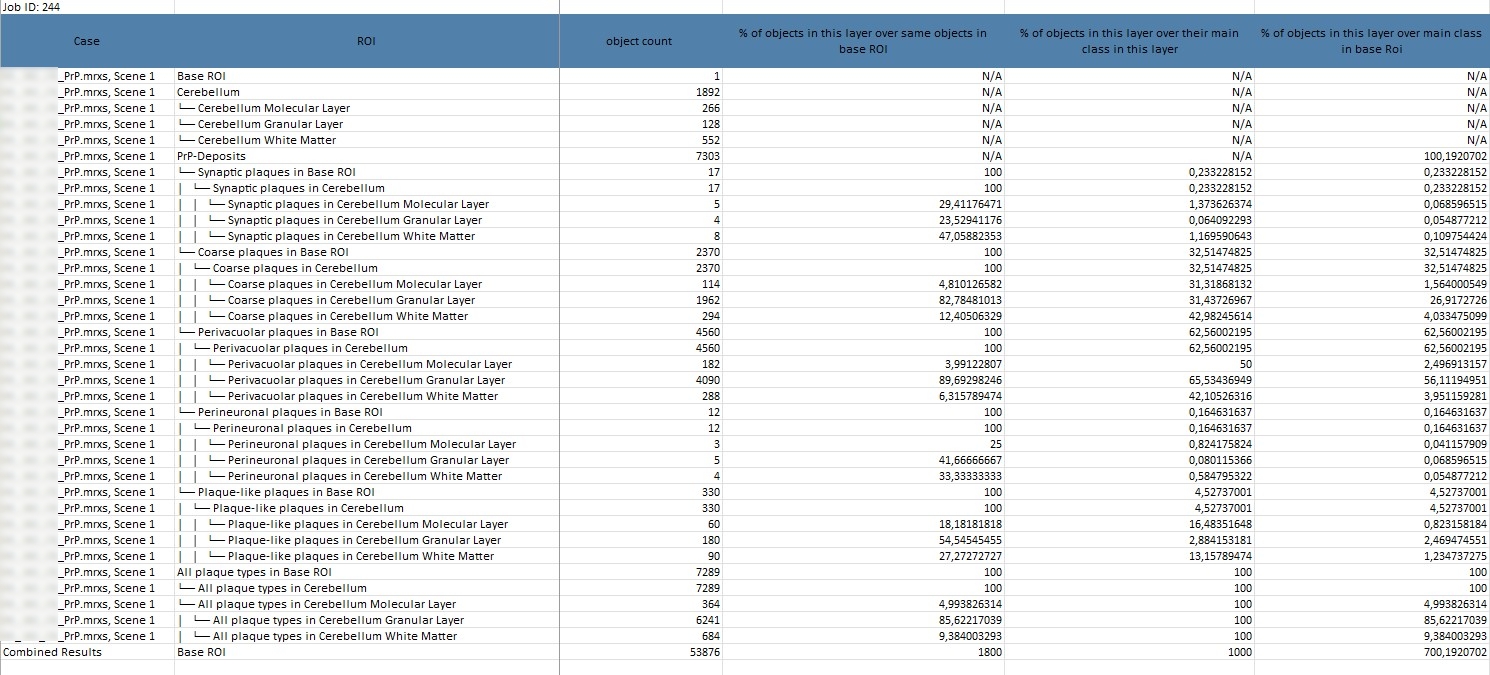
Detaillierte Information zur Tabelle:
Case: Die untersuchte Probe oder Szene.
ROI (Region of Interest): Die spezifische Region oder Schicht, z. B. die „Cerebellum Molecular Layer“.
Total Area (µm²) und Percentage of area of this layer: Diese Werte geben Auskunft über die Fläche, die die Strukturen innerhalb eines Layers einnehmen.
Object Count: Gibt an, wie viele Objekte in einem bestimmten Layer vorhanden sind, was Aufschluss über die Dichte der Strukturen gibt.
% of area of this layer over area of same object in Base ROI und % of objects in this layer over same objects in Base ROI: Diese Werte sind entscheidend für den Vergleich der Verteilung von Objekten in einem Layer mit dem gesamten untersuchten Bereich.
% of objects in this layer over their main class in this layer und % of objects in this layer over their main class in Base ROI: Diese Angaben zeigen die relative Verteilung und Konzentration der Objekte innerhalb eines Layers im Vergleich zur Hauptkategorie und der gesamten Region.
Shape-Faktor: Erfasst die Form und Rundheit der Objekte, was wichtig für die Analyse der Strukturen ist.
Diese Daten helfen dabei, die Verteilung und Dichte von Strukturen im Cortex zu analysieren, und sind entscheidend, um Unterschiede zwischen verschiedenen Layern zu erkennen – ein wesentlicher Schritt für die Untersuchung von Krankheitsmustern.
Rückschlüsse auf CJK-Subtypen mithilfe der HSA KIT-Software:
Das Hauptziel dieser Analyse, die mit der HSA KIT Software durchgeführt wird, ist es, mithilfe der genannten Metriken Rückschlüsse auf spezifische Subtypen von CJK zu ziehen. Da unterschiedliche Subtypen signifikante Unterschiede in der Anzahl und Verteilung von Strukturen in bestimmten Schichten zeigen können, ermöglicht die Analyse dieser Unterschiede die Klassifikation der Subtypen durch KI.
Durch den Vergleich der verschiedenen Regionen und Schichten sowie die statistische Auswertung der Formen und Verteilungen, die mit dem HSA KIT durchgeführt wird, wird eine präzisere Diagnose und Klassifikation der Subtypen möglich.
Ergänzend werden weitere Berechnungen angewendet. Detaillierte Informationen finden Sie hier:
Area results
Total Area
The sum of all polygon areas.
$$\text{Total Area} = \sum_{i=1}^{n} \text{Area}_i$$
Percentage Area of Base ROI
The percentage of the total area of polygons relative to the base ROI.
$$\text{Percentage Area} = \left( \frac{\text{Total Area}}{\text{Base ROI Area}} \right) \times 100 \%$$
Minimum Area
The smallest polygon area.
$$\text{Minimum Area} = \min(\text{Area}_1, \text{Area}_2, \ldots, \text{Area}_n)$$
Maximum Area
The largest polygon area.
$$\text{Maximum Area} = \max(\text{Area}_1, \text{Area}_2, \ldots, \text{Area}_n)$$
Average Area
The mean area of all polygons.
$$\text{Average Area} = \frac{\sum_{i=1}^{n} \text{Area}_i}{n}$$
Median Area
The median area of all polygons.
$$\text{Median} =
\begin{cases}
\text{Area}_{\left(\frac{n+1}{2}\right)} & \text{if } n \text{ is odd} \\
\frac{\text{Area}_{\left(\frac{n}{2}\right)} + \text{Area}_{\left(\frac{n}{2} + 1\right)}}{2} & \text{if } n \text{ is even}
\end{cases}$$
Mode Area
The most frequently occurring area value.
$$\text{Mode Area} = \text{The value that appears most frequently in the dataset}$$
Standard Deviation (StdDev) Area
The measure of dispersion of polygon areas.
$$\text{StdDev} = \sqrt{\frac{1}{n} \sum_{i=1}^{n} (\text{Area}_i – \text{Average Area})^2}$$
Variance of Area
The square of the standard deviation.
$$\text{Variance} = \frac{1}{n} \sum_{i=1}^{n} (\text{Area}_i – \text{Average Area})^2$$
Mean Absolute Deviation of Area
The average of the absolute deviations from the mean.
$$\text{MAD} = \frac{1}{n} \sum_{i=1}^{n} |\text{Area}_i – \text{Average Area}|$$
Skewness
The measure of the asymmetry of the distribution of area values.
Kurtosis
The measure of the „tailedness“ of the distribution of area values.
Object Size Quartiles (1st, 2nd, 3rd)
The quartile values of polygon areas.
Interquartile Range (1st – 3rd)
The range between the first and third quartile.
$$\text{IQR} = \text{Q3} – \text{Q1}$$
Decile Sizes (1st to 9th)
Values that divide the dataset into ten equal parts.
$$\text{D1} = \text{Area}_{\left(\frac{n+1}{10}\right)}$$
$$\text{D2} = \text{Area}_{\left(\frac{2(n+1)}{10}\right)}$$
$$\text{D3} = \text{Area}_{\left(\frac{3(n+1)}{10}\right)}$$
$$\text{D4} = \text{Area}_{\left(\frac{4(n+1)}{10}\right)}$$
$$\text{D5} = \text{Area}_{\left(\frac{5(n+1)}{10}\right)}$$
$$\text{D6} = \text{Area}_{\left(\frac{6(n+1)}{10}\right)}$$
$$\text{D7} = \text{Area}_{\left(\frac{7(n+1)}{10}\right)}$$
$$\text{D8} = \text{Area}_{\left(\frac{8(n+1)}{10}\right)}$$
$$\text{D9} = \text{Area}_{\left(\frac{9(n+1)}{10}\right)}$$
Confidence Intervals of Area
The range within which the true mean of the population lies with a certain confidence level.
$$\text{CI} = \text{Average Area} \pm (z \times \frac{\text{StdDev}}{\sqrt{n}})$$
Shape Factor
A measure of the compactness of the shape.
Area to Perimeter Ratio
The ratio of area to perimeter.
Eccentricity
The ratio of the distance between the foci of the ellipse and its major axis length.
$$\text{Eccentricity} = \sqrt{1 – \frac{b^2}{a^2}}$$
Other results
Object count
The number of polygons
Object density
The number of polygons per unit area.
$$\text{Object Density} = \frac{\text{Number of Polygons}}{\text{Total Area}}$$
Disperion index
A measure of how polygons are dispersed over the area.
$$\text{Dispersion Index} = \frac{\text{Variance of Polygons per Unit Area}}{\text{Mean Polygons per Unit Area}}$$
Clustering analysis
A measure of how polygons are clustered together.
$$\text{Clustering Index} = \frac{\text{Variance of Polygons in Sub-regions}}{\text{Mean Polygons in Sub-regions}}$$
Maximum perimeter
The largest perimeter of the polygons.
$$\text{Maximum Perimeter} = \max(\text{Perimeter}_1, \text{Perimeter}_2, \ldots, \text{Perimeter}_n)$$
Average perimeter
The mean perimeter of all polygons.
$$\text{Average Perimeter} = \frac{\sum_{i=1}^{n} \text{Perimeter}_i}{n}$$
Median perimeter
The median perimeter of all polygons.
$$\text{Median Perimeter} =
\begin{cases}
\text{Perimeter}_{\left(\frac{n+1}{2}\right)} & \text{if } n \text{ is odd} \\
\frac{\text{Perimeter}_{\left(\frac{n}{2}\right)} + \text{Perimeter}_{\left(\frac{n}{2} + 1\right)}}{2} & \text{if } n \text{ is even}
\end{cases}$$stdev perimeter
The measure of dispersion of the perimeters of the polygons.
$$\text{StdDev Perimeter} = \sqrt{\frac{1}{n} \sum_{i=1}^{n} (\text{Perimeter}_i – \text{Average Perimeter})^2}$$
Variance of perimeter
The square of the standard deviation of the perimeters.
$$\text{Variance of Perimeter} = \frac{1}{n} \sum_{i=1}^{n} (\text{Perimeter}_i – \text{Average Perimeter})^2$$
Data Collection and Preprocessing
Um eine pixelgenaue Präzision sicherzustellen, bietet das HSA KIT eine intuitive Benutzeroberfläche sowie professionelle Annotationstools auf höchstem Niveau. Dadurch wird der gesamte Analyseprozess optimiert, indem Techniken standardisiert, Konsistenz gewährleistet und Wiederholbarkeit gefördert werden.
Das Programm konzentriert sich auf die Objekterkennung und -identifikation, die beide zentrale Bestandteile der Bildverarbeitung sind. Objekterkennungsalgorithmen analysieren Bilder, um relevante Objekte zu identifizieren und zu kategorisieren, was verwertbare Daten für weitere Untersuchungen und Entscheidungen liefert.


Workflow mit HSA KIT
Das Analysieren von Proben und Digitalisieren von Slides war noch nie so einfach. Das HSA KIT bietet eine unvergleichliche Erfahrung für Anwender, die mit den heutigen fortschrittlichen Alternativen Schritt halten und die Effizienz ihrer Arbeitsabläufe verbessern möchten. Das HSA-Team geht weit über die Erwartungen hinaus, um seine Kunden zufriedenzustellen – von der Installation und Integration der Software bis hin zu kontinuierlicher Unterstützung und Updates.
Die auf dem HSA KIT basierende KI-Analyse bietet:
- Standardisierte Verfahren mit subjektiver/objektiver Bewertung
- Extraktion signifikanter Merkmale aus Rohdaten und Erstellung aussagekräftiger Darstellungen für das Training von KI-Modellen
- Modulauswahl und Konfiguration mit minimalem Programmieraufwand
- Einfache Softwarebedienung: Trainieren, Annotieren und Automatisieren
- Schnelle und effiziente Auswertung verschiedener medizinischer Bilder, was die Zeit für Diagnose oder Behandlung erheblich verkürzt
- Automatisch generierte Berichte

For more information or placing an order, contact : sales@hs-analysis.com