Acht Millionen Patienten in Deutschland (800 Millionen weltweit) leiden unter chronischen Hauterkrankungen. Etwa 2 % dieser Patienten leiden an Psoriasis und 2 % an Neurodermitis. An den Kliniken für Dermatologie des Universitätsklinikums Mannheim (UMM) und des Universitätsklinikums Würzburg (UKM) führt dies zu mindestens 10.000 Patientenkontakten pro Jahr. Die Wartezeiten für Patienten auf einen universitären Behandlungstermin betragen im Durchschnitt über 6 Monate. Der Zugang zum Gesundheitssystem und eine optimale und schnelle Therapie sind daher erschwert.
Die Analyse der Psoriasis-Hauterkrankung in der HSA KIT Deep Learning Software ermöglicht es, eine durch Psoriasis verursachte Haut zu erkennen. Psoriasis ist eine chronische Autoimmunerkrankung, die hauptsächlich die Haut betrifft und rote, schuppige Flecken verursacht. Spezialisten bei HS Analysis sind in der Lage, fortschrittliche Deep Learning KI-Software zu verwenden, um diese Krankheit zu diagnostizieren und in Kliniken, Institutionen und Gesundheitseinrichtungen einzusetzen.

Das Wissen um Ihren Psoriasis-Typ kann Ihrem Gesundheitsdienstleister helfen, einen Behandlungsplan zu erstellen. Die meisten Menschen erleben zu einem Zeitpunkt einen Typ, aber es ist möglich, mehr als einen Typ von Psoriasis zu haben.
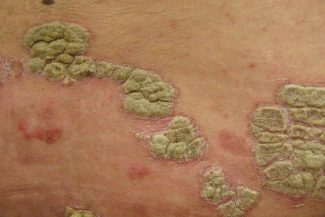
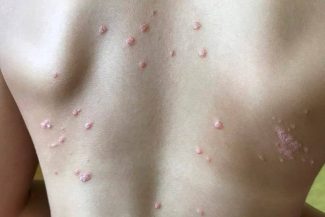
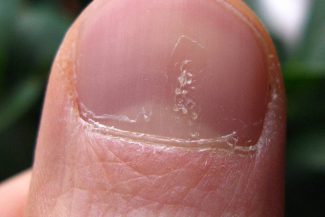
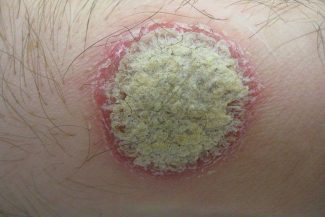
Ground Truth Data (GTD)
Ground Truth Data (GTD) bezieht sich auf Daten, die manuell annotiert oder gekennzeichnet werden und zum Trainieren, Validieren oder Testen von Machine-Learning-Modellen verwendet werden. Bei einem 2D-Bild besteht Ground Truth Data aus präzisen Anmerkungen oder Labels, die die Objekte, Muster oder Merkmale im Bild beschreiben.
In Objekterkennungsszenarien würde Ground Truth Data für ein 2D-Bild beispielsweise Bounding-Boxen oder Segmentierungsmasken um jedes relevante Objekt im Bild beinhalten. Zusätzlich würde es entsprechende Klassenlabels für jedes Objekt enthalten. Bei Bildklassifizierungsaufgaben würde Ground Truth Data aus zugewiesenen Klassenlabels für das Bild bestehen.
Diese Tabelle beschreibt die gesamten Annotationen pro Datei und auch die Gesamtanzahl der Annotationen:
| Dateinummer | Annotiertes Bild/Basis-ROI | Anzahl der Haut-Anmerkungen | Prozentualer Anteil der Gesamtanmerkungen | Anzahl der Hyperpigmentations-Anmerkungen | Prozentualer Anteil der Gesamtanmerkungen | Anzahl der entzündeten Anmerkungen | Prozentualer Anteil der Gesamtanmerkungen |
| 001 | 88 | 124 | 1,45% | 118 | 1,38% | 401 | 4,70% |
| 002 | 94 | 134 | 1,57% | 53 | 0,62% | 435 | 5,10% |
| 003 | 97 | 104 | 1,22% | 43 | 0,50% | 315 | 3,69% |
| 004 | 94 | 152 | 1,78% | 99 | 1,16% | 330 | 3,87% |
| 006 | 92 | 130 | 1,52% | 52 | 0,61% | 426 | 4,99% |
| 007 | 96 | 125 | 1,47% | 23 | 0,27% | 211 | 2,47% |
| 009 | 88 | 124 | 1,45% | 0 | 0,00% | 302 | 3,54% |
| 010 | 88 | 101 | 1,18% | 15 | 0,18% | 304 | 3,56% |
| 011 | 91 | 106 | 1,24% | 38 | 0,45% | 238 | 2,79% |
| 013 | 89 | 119 | 1,40% | 8 | 0,09% | 516 | 6,05% |
| 014 | 92 | 115 | 1,35% | 8 | 0,09% | 246 | 2,89% |
| 015 | 84 | 105 | 1,23% | 18 | 0,21% | 392 | 4,59% |
| 016 | 90 | 107 | 1,25% | 2 | 0,02% | 232 | 2,72% |
| 017 | 98 | 115 | 1,35% | 24 | 0,28% | 175 | 2,05% |
| 018 | 86 | 109 | 1,28% | 1 | 0,01% | 328 | 3,85% |
| 020 | 90 | 116 | 1,36% | 0 | 0,00% | 193 | 2,26% |
| 021 | 75 | 95 | 1,11% | 18 | 0,21% | 237 | 2,78% |
| 022 | 94 | 118 | 1,38% | 4 | 0,05% | 176 | 2,06% |
| 023 | 89 | 108 | 1,27% | 33 | 0,39% | 308 | 3,61% |
| Gesamt | 1715 | 2207 | 25,87% | 557 | 6,53% | 5765 | 67,58% |
| Die Gesamtzahl aller Anmerkungen | 8529 | ||||||
Die erste Spalte beschreibt die Dateinummern, jede Datei besteht aus 100 Bildern, und die zweite Spalte beschreibt das interessierende Gebiet aus diesen 100 Bildern. Wir haben einige der Bilder aus bestimmten Gründen ausgeschlossen, und die dritte Spalte beschreibt die Hautanmerkungen mit ihren Prozentanteilen in der vierten Spalte. In der fünften Spalte werden die Hyperpigmentationsanmerkungen mit ihren Prozentanteilen in der sechsten Spalte beschrieben, und in der siebten Spalte werden die entzündeten Bereiche (Plaques) mit ihren Prozentanteilen in der achten Spalte beschrieben. Die vorletzte Zeile beschreibt die Gesamtanzahl der Anmerkungen jeder Klasse, und die letzte Zeile beschreibt die Gesamtanzahl aller Anmerkungen.
Dataset Selection
Nach der Erstellung von GTD wurden die Einstellungen in dieser Tabelle für 3 verschiedene Architekturen verwendet, um ein Modell zu trainieren.
| Modelltyp | Datensatzansatz | Epochen | Lernrate | Batchgröße |
| Segmentierung | Vollbild | 100 | 0,0001 | 2 |
Künstliche Intelligenz
HSA KIT arbeitet an der Entwicklung von KI-Maschinen und Deep Learning-Methoden, die auf die Simulation menschlicher Intelligenz in Maschinen abzielen, die darauf programmiert sind, Aufgaben auszuführen, die typischerweise menschliche Intelligenz erfordern. KI-Systeme sind darauf ausgelegt, ihre Umgebung wahrzunehmen, darüber nachzudenken und entsprechende Maßnahmen zu ergreifen, um bestimmte Ziele zu erreichen. Deep Learning kann genutzt werden, um Hautkrankheiten zu definieren oder zu identifizieren, indem die Fähigkeit genutzt wird, komplexe Muster und Merkmale aus großen Datensätzen zu lernen.
Die Berührung von HS Analysis
Eine Schlüsseltechnologie der automatischen Interpretation von Gewebeproben in der HS Analysis Software ist die neueste künstliche Intelligenz. Wir entwickeln ein DL in der Cloud, um Smartphone-Bilder in 2D zu analysieren, aber auch Oberflächenmerkmale (Heatmaps und damit 3D) mit CNNs. Wir haben die Fähigkeit, Ground Truth Data zu erstellen und Modelle sowohl für die Hauterkennung als auch für die Erkennung von Plaques zu trainieren.
Wie wir unsere KI entwickeln: Zunächst sammeln wir echte Bilddaten und annotieren sie basierend auf Farben. Für die Haut verwenden wir Gelb und annotieren alle sichtbaren Hautbereiche im Bild, um das bestmögliche KI-Modell mit minimalen Fehlern zu erhalten.
Annotierungsbeispiele



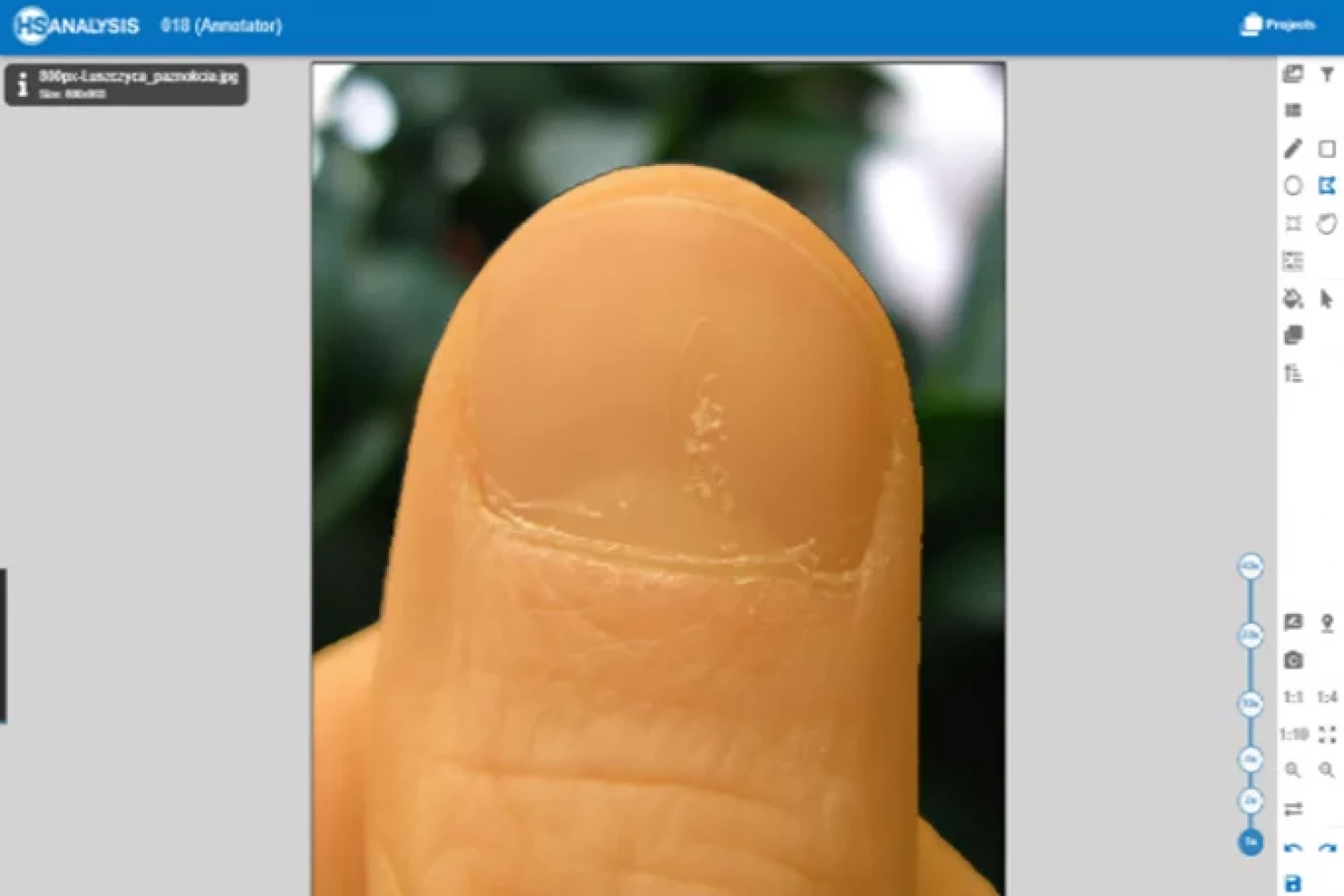
Der nächste Schritt ist die Annotation von entzündeten Bereichen auf der Haut mit roter Farbe, und dann trainieren wir das Modell, um automatisch die Plaques zu erkennen.




Ergebnisse
Dies ist das Ergebnis des Haut- und Plaques-Modells nach dem Training und der Anwendung auf andere Hautbereiche mit unterschiedlicher Opazität:




Wir sehen hier eine Segmentierung der Haut in Orange, die durch Deep Learning erkannt wurde, und auch eine andere Farbe, die in Rot gezeigt wird, die die Plaques beschreibt, die durch das zweite Deep Learning erkannt wurden. Beide Modelle, die mit fortschrittlichen Techniken trainiert wurden, können die gesamte Haut und die entzündeten Bereiche erkennen.
Modelltraining
Wir trainieren jedes Modell einzeln. Dann testen und optimieren wir die Modelle, wir verwenden unseren Testdatensatz, um zu bewerten, wie gut unser KI-Modell die Aufgabe erfüllt, Psoriasis von anderen Hauterkrankungen und normaler Haut zu unterscheiden.
In diesem Bild sehen wir den Entwicklungsprozess der KI, und dies ist eines unserer Beispiele, nicht nur dieses Bild, wir wenden das Modell auf verschiedene Bilder und Hautbereiche an, dies war nur ein Beispiel für die Entwicklung.
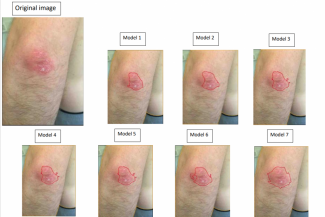
Während des Trainings haben wir Datensätze, die aus verschiedenen Bildern bestehen, jedes Bild wird 100 Mal erkannt.
Arten des Trainings umfassen:
- Klassifikation: Objekte verschiedenen Klassen zuordnen
- Objekterkennung: Objekt erkennen und Begrenzungsrahmen darum zeichnen
- Segmentierung: Objekt erkennen und genaue Grenze um Objekt zeichnen
- Instanz-Segmentierung: Segmentierung + Unterscheidung zwischen berührenden Objekten
Augmentierungen
- Horizontale Spiegelung
Geeignet für: Naturszenen, Tiere, Objekte ohne spezifische Orientierung.
Nicht geeignet für: Text, Szenen mit klarer Links-nach-Rechts- oder Rechts-nach-Links-Kontext, Bilder mit Richtungsschildern usw. - Vertikale Spiegelung
Geeignet für: Spiegelungen im Wasser, einige abstrakte Kunstwerke.
Nicht geeignet für: Die meisten realen Bilder, da eine vertikale Spiegelung sie unnatürlich erscheinen lassen kann. Zum Beispiel das Umkehren einer Person. - Rotation
Kleine Rotationen (z.B. ±10°) eignen sich für die meisten Bilder, um den Effekt des Kippens einer Kamera zu simulieren.
Große Rotationen (z.B. 90°, 180°) können den Kontext verändern und sind möglicherweise nicht für alle Bilder geeignet. Zum Beispiel würde das Drehen eines Porträts einer Person um 90° oder 180° merkwürdig aussehen.

Wir wählen den Instanz-Segmentierungsmodelltyp, der Objekte erkennt, die genaue Grenze um Objekte zieht und zwischen berührenden Objekten unterscheidet. Die Struktur hängt von der gewünschten KI ab, sei es Haut oder entzündet, und wir verwenden einige Augmentierungen (horizontale Spiegelung, vertikale Spiegelung und Rotation), um Überanpassung zu verhindern, und wir trainieren die neueste Modellversion basierend auf den bestehenden Versionen.
Die Zukunft der HSA KIT KI
Ein sehr wichtiger Aspekt dieses Projekts ist es, das KI-Modell in Zukunft zu verbessern, und es gibt viele Ideen, die wir integrieren und entwickeln können, um die Qualität und Vielseitigkeit des KI-Modells zu verbessern, um Haut und Plaques in vielen verschiedenen Fotos und verschiedenen Arten von Rauschen und Artefakten zu erkennen und trotz dieser Artefakte ein besseres und genaueres Ergebnis zu erzielen. Wir betrachten die Herausforderungen und Artefakte und finden heraus, dass es verschiedene Arten von ihnen gibt, und die Aufgabe besteht darin, dass die KI in der Lage ist, die richtigen Ziele trotz des Vorhandenseins dieser Artefakte im Bild zu erkennen.
Diese Herausforderungen in Zukunft zu meistern, wird sicherlich dazu führen, dass das KI-Modell extrem genau und mit modernsten Anmerkungen ausgestattet ist.
Hier sind einige dieser Arten von Rauschen oder Artefakten, die wir verbessern möchten:

Bildunschärfe
Unschärfe ist eines der häufigsten Probleme, die die KI daran hindern, die Haut und die Plaques korrekt zu erkennen. Wenn dieses Problem gelöst wird, kann die Haut und die Plaques besser von anderen Objekten im Hintergrund erkannt werden.

Beleuchtung und Schatten
Ein weiteres sehr häufiges Artefakt ist das Vorhandensein von Licht und Schatten sowie der unterschiedliche Kontrast, der auf dem Bild auftritt und die Erkennung beeinträchtigt.

Unscharfe Bilder
Fast alle Bilder, die zum Training des KI-Modells verwendet wurden, stammen von Smartphones, und manchmal senden Patienten Bilder, die unscharf sind.

Kanten- und Randgenauigkeit
Um ein ausgezeichnetes und hochgenaues Modell zu haben, ist es sehr wichtig, die Kanten und Ränder genau zu annotieren, um keine anderen unerwünschten Objekte oder Pixel einzuschließen, die die Modellgenauigkeit beeinträchtigen könnten.
Unerwünschte Bilder
Die Möglichkeit, Bilder, die nicht für die Annotation geeignet sind, automatisch auszuschließen, sei es, weil sie keine Haut enthalten oder die Identität des Patienten sichtbar ist, sowie unangemessene oder private Bilder, die gesendet werden, ist entscheidend.
Erklärbare Künstliche Intelligenz (xAI)
Das Hauptziel von xAI ist es, verständliche KI-Entscheidungen zu erreichen. Dies wird durch Methoden wie Feature Visualization, Feature Attribution und die Verwendung von Ersatzmodellen realisiert. Diese Techniken zielen darauf ab, visuell zu zeigen, welche Teile der Daten das Modell als wichtig erachtet, einzelnen Datenmerkmalen basierend auf ihrer Auswirkung auf das Ergebnis Bewertungen zuzuweisen und komplexe Modellentscheidungen mithilfe einfacher, interpretierbarer Modelle zu approximieren. Die Bedeutung von xAI kann nicht hoch genug eingeschätzt werden; es fördert Vertrauen, unterstützt die Modellvalidierung und gewährleistet die Einhaltung von Vorschriften, die Transparenz bei automatisierten Entscheidungen vorschreiben.


Aktivierungsmatrizen
Dies sind mehrdimensionale Arrays, die die Ausgangswerte von Neuronen in den Schichten eines neuronalen Netzwerks darstellen, die oft in den Faltungsschichten eines CNN zu sehen sind. Sie geben Aufschluss darüber, wie Eingabedaten im Netzwerk verarbeitet und transformiert werden. Die Visualisierung dieser Arrays als Heatmaps kann dazu beitragen, das Feature-Detection-Verhalten des Netzwerks zu verstehen und ist nützlich für Debugging und Optimierung.
Class Activation Mapping (CAM)
Das Hauptziel von CAM ist es, herauszufinden, welche Regionen in einem Bild eine entscheidende Rolle bei der Bestimmung seiner Klassifizierung durch ein CNN spielen. Dies wird erreicht, indem die Gewichte aus der globalen Durchschnittspooling-Schicht eines CNN verwendet werden, um eine Heatmap des Bildes zu erzeugen, die die wichtigen Regionen hervorhebt. Indem die Regionen in einem Bild identifiziert werden, die seine Klassifizierung wesentlich beeinflussen, ist CAM ein leistungsfähiges Werkzeug zur visuellen Interpretation von CNN-Entscheidungen und stellt sicher, dass das Modell sich auf die richtigen Bildmerkmale konzentriert.

Dieses Video zeigt, wie wir die Haut und den entzündeten Bereich annotiert haben. Nach dem Annotierungsprozess haben wir sowohl Haut- als auch Plaques-Modelle trainiert und dann die Modelle auf verschiedenen Hautbereichen angewendet.