
Infolge der proteolytischen Verarbeitung des Amyloid-Vorläuferproteins und der anschließenden Hyperphosphorylierung des Tau-Proteins führt die Alzheimer-Krankheit dazu, dass sich das Peptid Beta-Amyloid in den am stärksten betroffenen Teilen des Gehirns, dem medialen Temporallappen und den neokortikalen Strukturen, ansammelt. Dies ist eine der Hauptursachen für eine Reihe von Ereignissen, die zu mitochondrialer Dysfunktion, synaptischer Dysfunktion und oxidativem Stress führen. Akute COVID-19-Infektionen, die zum Tod führen, treten häufiger bei Patienten mit Alzheimer-Krankheit auf.
Laut Transkriptionsprofilen und histologischen Beweisen, die Proteine im Vagusnerv und Schäden an den Vagusnuklei sowie klinische Daten, die auf eine Beeinträchtigung des Vagusnervensystems hinweisen, stört COVID-19 das Vagusnervensystem.

Das Verfahren zur Transkriptionsprofilierung ist in der obigen Abbildung dargestellt. Die Vulkan-Karte illustriert Gene, die erhöht (rot) und herunterreguliert (blau) sind. Eine Heatmap der 20 am stärksten hochregulierten Gene im Vagusnerv von SARS-CoV-2-Patienten und Kontrollen ist ebenfalls enthalten.
Morphologien von Beta-Amyloid
Die allgemein akzeptierten Standards für eine neurobiologische Diagnose der Alzheimer-Krankheit umfassen Verfahren zur Bestimmung der Menge und des Ortes von Plaques.
Beta-Amyloid kann folgende Morphologien annehmen:
- Kern
- Punktiert
- Vaskulär
- Diffus
Die Identifizierung des Fortschreitens der Krankheit und der Pathophysiologie kann auf genaueren Messungen der Plaque-Morphologien und -Klassen basieren, die auch Orientierung und Einblick in die Krankheitsmechanismen bieten können.
Morphologie des HLA-Signals
Die menschlichen Leukozytenantigene-Signale oder HLA-Signale sind genetische Kennzeichen, die auf der Oberfläche von Körperzellen vorhanden sind. Die Fähigkeit des Immunsystems, zwischen körpereigenen Zellen und fremden Dingen wie Viren, Bakterien oder transplantierten Geweben zu unterscheiden, hängt entscheidend von diesen Markern ab.
HLA-Signale nehmen die folgenden Morphologien an:
- Mikroglia-Prozess
- Aktivierte Mikroglia
- Ruhende Mikroglia
- Mikroglia-Knötchen
- Phagozytische Mikroglia
Zur Unterscheidung werden sie nach der Form der HLA-Signale, die auf der Zelloberfläche vorhanden sind, annotiert.
Morphologie des TAU-Proteins
Tau ist ein Protein, das zur Stabilisierung der Struktur von Neuronen beiträgt. Wenn es jedoch abnormal akkumuliert, kann es zu neurodegenerativen Krankheiten wie Alzheimer führen. Das Vorhandensein von Tau bei Covid-19-Patienten deutet darauf hin, dass das Virus langfristige kognitive Auswirkungen haben könnte.
TAU-Protein nimmt die folgenden Morphologien an:
- Tau-Verwicklungen
- Pre-Verwicklungen
- Tau-Neurotisch
- Tau-Fäden
Morphologie von Cortex, WM und Meningen
Die Begriffe „Cortex“, „WM“ (Weiße Substanz) und „Meningen“ stammen aus der Neuroanatomie und beschreiben die Struktur von konvolutionalen neuronalen Netzwerken (CNNs), die häufig für Bildanalyse- und Computer-Vision-Aufgaben verwendet werden. Die Anordnung und Funktion verschiedener Komponenten einer neuronalen Netzwerkarchitektur werden metaphorisch unter Verwendung der folgenden Begriffe beschrieben.
Cortex, WM und Meningen nehmen die folgenden Morphologien an:
- Cortex: In der Morphologie des Deep Learning bezieht sich der Begriff „Cortex“ typischerweise auf die äußerste Schicht eines neuronalen Netzwerks, die den initialen Schichten des Netzwerks entspricht, die für die Merkmalsextraktion verantwortlich sind. Genau wie der Kortex des Gehirns sensorische Informationen verarbeitet und bedeutungsvolle Merkmale extrahiert, verarbeitet der „Cortex“ des Netzwerks Eingabedaten und extrahiert relevante Merkmale.
- WM (Weiße Substanz): In diesem Zusammenhang steht „WM“ für „Weiße Substanz“ und wird verwendet, um die Zwischenschichten eines neuronalen Netzwerks zu beschreiben. Diese Schichten werden als „weiße Substanz“ bezeichnet, weil sie oft als Kanäle für den Informationsfluss betrachtet werden, ähnlich wie die weiße Substanz im Gehirn verschiedene Regionen verbindet. In einem neuronalen Netzwerk sind diese Schichten für mittlere Merkmalsrepräsentationen und die Verbindung verschiedener Teile des Netzwerks verantwortlich.
- Meningen: „Meningen“ ist ein weiterer entlehnter Begriff, der in der Morphologie des Deep Learning verwendet werden kann, um schützende Schichten oder Einschränkungen zu beschreiben, die auf das neuronale Netzwerk angewendet werden. Genau wie die Meningen das Gehirn und das Rückenmark schützen, könnte „Meningen“ in diesem Zusammenhang Schichten von Regularisierung oder Einschränkungen bedeuten, die auf das neuronale Netzwerk angewendet werden, um sicherzustellen, dass es gut generalisiert und Überanpassung vermeidet.
Diese Begriffe werden nicht universell übernommen und ihre Verwendung kann unter Forschern und Pädagogen variieren. Sie werden metaphorisch verwendet, um die Idee verschiedener Schichten oder Teile innerhalb eines neuronalen Netzwerks und deren Rolle bei der Verarbeitung von Daten und der Extraktion von Merkmalen zu vermitteln, indem sie eine Analogie zur Struktur und Funktion des menschlichen Gehirns ziehen.

Glial fibrillary acidic protein (GFAP)
Das grundlegende Protein GFAP, oder Glial Fibrillary Acidic Protein, ist hauptsächlich in Astrozyten vorhanden, spezialisierten Zellen im Zentralnervensystem. Während GFAP ein wichtiger Biomarker in der Gehirnforschung ist und hauptsächlich mit neurologischen Prozessen in Verbindung steht, wird es im Deep Learning selten verwendet. Stattdessen nutzen Deep Learning-Modelle eine Vielzahl von datengesteuerten Methoden und neuronalen Netzwerken, um komplexe Probleme zu lösen.
HSA KIT
Die HSA KIT Software, „Neuro COVID 19“ Modul, konzentriert sich auf Next-Generation-Sequenzierungsdaten, indem sie ein besseres Verständnis von Störungen bietet.
Unser „Neuro COVID 19“ Modul verwendet KI, um durch Training anhand bekannter Informationen ein Trainingsdatensatz zu erstellen, was von der Software durch KI unterstützt wird. Die KI kann automatisch unbeschriftete Sequenzen erkennen. Anschließend werden zusätzliche Daten, die den Daten im Trainingsmodell ähnlich sind, mithilfe des passenden Deep Learning entdeckt. Dies bietet einen Überblick über die klinische Bedeutung und Schwere der zugehörigen Datenvarianten, wodurch die prädiktive Analytik Funktion Ärzten, Forschern und Labordiagnostik Unterstützung bietet.



Das „Neuro COVID 19“ Modul erkennt die Klassen von Beta-Amyloid im Cortex. Plaque-Kern in orange, Plaque-punktiert in rot und Plaque-diffus in grün.
Das „Auge“-Symbol wird verwendet, um Strukturen ein- und auszublenden, Klassen zur Anzeige zu deaktivieren und die gewünschte Klasse zur Anzeige zu aktivieren.

Das „TAU“-Modul erkennt die Klassen von Tau im Kortex. Pre Tangle in grüner Farbe, Tau Tangle in orange-blauer Farbe, Tau Neuritic in oranger Farbe und Undefined in roter Farbe.

Das „Neuro COVID 19“-Modul erkennt die Klassen von HLA im Cortex. Aktivierte Mikroglia in grüner Farbe, Mikroglia-Prozess in orange Farbe und Phagozytische Mikroglia in hellgrüner Farbe.

Das Modul der konvolutionalen neuronalen Netzwerke (CNNs) erkennt Cortex, WM und Meningen. Cortex in lila Farbe, WM in grüner Farbe und Meningen in brauner Farbe.
Deep Learning (DL)

Die Beziehung zwischen KI, maschinellem Lernen und Deep Learning. KI ist ein Begriff, der Ansätze beschreibt, die es Computern ermöglichen, menschliches Verhalten nachzuahmen. Maschinelles Lernen verwendet Algorithmen, die auf Daten trainiert wurden, um Computern Vorhersagen oder Klassifikationen zu ermöglichen. Deep Learning ist eine Form des maschinellen Lernens, die mehrschichtige neuronale Netzwerke verwendet, um Daten zu analysieren und Muster zu erkennen, ähnlich wie das menschliche Gehirn arbeitet. Das Design des neuronalen Netzwerks basiert auf der Struktur des menschlichen Gehirns.
Ground Truth Data (GTD)

GTD bezieht sich auf die wahre Natur des Problems, das von einem maschinellen Lernmodell adressiert wird, und ist notwendig, damit das Modell aus beschrifteten Daten lernen kann. Je mehr annotierte Daten vorhanden sind, desto besser werden die Algorithmen funktionieren. Bei überwachten Lernalgorithmen müssen menschliche Evaluatoren oder Annotatoren häufig Ground-Truth-Labels entwickeln, was teuer und zeitaufwendig sein kann. Der Text vergleicht GTD auch mit dem Treibstoff, der für den Motor eines Schiffes benötigt wird, wobei DL-Modelle der Motor und die großen Datenmengen der Treibstoff sind. DL-Modelle neigen dazu, sich mit zunehmender Menge an Trainingsdaten zu verbessern, und das Zeitalter der Big Data bietet enorme Möglichkeiten für neue DL-Fortschritte.
Kosten- und Verlustfunktion
Das Ziel bei der Entwicklung eines DL-Modells ist es, den Fehler zwischen den Vorhersagen und den tatsächlichen Werten zu minimieren. Dies geschieht mithilfe von Verlustfunktionen, die mit jedem Trainingsexemplar verbunden sind. Die Kostenfunktion ist der Durchschnitt der Verlustfunktionwerte über alle Datensätze. Die Kostenfunktion wird optimiert, um den Fehler im DL zu reduzieren. Durch die Optimierung der Kostenfunktion können wir die besten Ergebnisse im DL erzielen.
Metriken
Die Matrizen, die wichtige Werkzeuge zur Bewertung der Leistung von maschinellen Lernmodellen sind. Konfusionsmatrizen werden erstellt, wenn Klassifikationsfehler vorliegen, und sie enthalten vier verschiedene Werte: Wahre Positive, Falsch-Negative, Falsch-Positive und Wahre Negative. Klassifikationsmetriken wie Sensitivität, Spezifität, Genauigkeit, Negativer Vorhersagewert und Präzision können basierend auf der Konfusionsmatrix berechnet werden.
Mittlere Durchschnittspräzision (mAP)
Die Formel für die Mittlere Durchschnittspräzision (mAP) basiert auf mehreren Submetriken, einschließlich der Konfusionsmatrix, dem Intersection over Union (IoU), Recall und Präzision. Sie berechnet den gewichteten Mittelwert der Präzisionen bei jedem Schwellenwert, wobei der Anstieg des Recall vom vorherigen Schwellenwert berücksichtigt wird. Die mAP wird berechnet, indem die AP für jede Klasse bestimmt und dann die Ergebnisse über viele Klassen hinweg gemittelt werden. Sie misst den Kompromiss zwischen Genauigkeit und Recall und ist ein nützliches Maß für die meisten Erkennungsanwendungen.
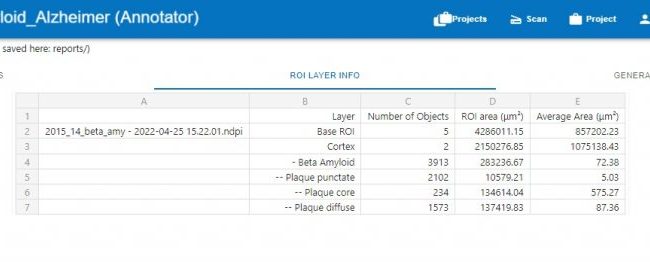
Erstellung von GTD

Die Proben, die für das DL-Modell verwendet wurden, wurden aus den Gehirnen verstorbener Personen durch Schneiden und Färben der Zellen mit verschiedenen Methoden gewonnen. Diese Folien wurden dann in digitale NDPI-Dateien umgewandelt und an uns gesendet, um ein DL-Modell zu erstellen. Um die für das DL-Modell erforderlichen GTD zu erstellen, wurden die NDPI-Dateien in die HSA KIT-Software geladen und der Zielbereich (Beta-Amyloid) annotiert und in die Kategorien Kern, Punktiert und Diffus klassifiziert. Das Modell wurde mit 4793 GTD trainiert, aber das war nicht gut genug, also wurden weitere GTD erstellt und das Modell erneut mit 9596 GTD trainiert. Die Klassenverteilung und Prozentsätze in den erstellten Daten sind in der untenstehenden Tabelle aufgeführt.
Auswahl des Datensatzes

Nach der Erstellung von GTD wurden die untenstehenden Einstellungen für 2 verschiedene Architekturen verwendet, um ein Modell zu trainieren.
HyperAmyNet
Das HSA KIT wurde verwendet, um Beta-Amyloid-Signale in Gehirnschnitten als WSI zu erkennen. Die Software umfasst ein DL-Modell namens HyperAmyNet, das sich auf die Segmentierung und Klassifizierung von Beta-Amyloid-Signalen konzentriert. Zwei Arten von HyperAmyNet wurden im HSA KIT implementiert: Typ 1, basierend auf der Mask R-CNN-Architektur, und Typ 2, basierend auf der ViT-Architektur.
Interpretation der Ergebnisse des trainierten Modells
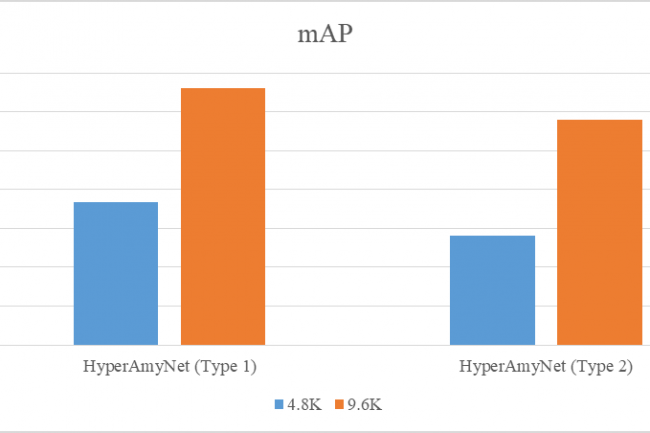
Die in der Tabelle unten dargestellten Einstellungen wurden ausgewählt, um die Modelle zu trainieren. Verlust und mAP wurden verwendet, um zwischen den Modellen zu vergleichen, wobei ein niedrigerer Verlust und eine höhere mAP wünschenswerte Eigenschaften für ein besseres Modell sind. Der Verlust und die mAP beider HyperAmyNet-Modelle (Typ 1 und Typ 2) wurden mit dem gemessenen Verlust für beide 4,8K und 9,6K GTD-Modelle verglichen. Die Ergebnisse zeigten, dass beide Modelle einen höheren Verlust hatten, wenn sie mit 4,8K GTD trainiert wurden, und einen niedrigeren Verlust, wenn sie mit 9,6K GTD trainiert wurden, wie in der Tabelle und dem Balkendiagramm unten gezeigt. Ebenso hatten beide Modelle eine höhere mAP, wenn sie mit 9,6K GTD trainiert wurden, und eine niedrigere mAP, wenn sie mit 4,8K GTD trainiert wurden, wie in der Tabelle und dem Balkendiagramm unten gezeigt. Diese Ergebnisse zeigen, dass die Menge an GTD ein wichtiger Faktor bei der Entwicklung eines guten Modells ist, wie bereits diskutiert wurde.


Visuelle Interpretation der Ergebnisse
Zu Beginn müssen die Ausgaben immer visuell überprüft werden. Es wird immer Zahlen geben, und Zahlen könnten zufällig vernünftig erscheinen, aber tatsächlich falsch sein. Visuelles Überprüfen von Anfang an und dann den Vergleich mit den Zahlen zu ziehen, ist der beste Weg, um der KI zu vertrauen und das beste Modell zu erhalten. Nach der Erstellung eines vertrauenswürdigen KI-Modells kann es zuverlässig, vollständig automatisiert und unter der Kontrolle der KI verwendet werden.

Die obigen Bilder der „Neuro COVID 19“-Ergebnistabelle und des Diagramms zeigen die Anzahl und den Prozentsatz jeder Klasse. Der Prozentsatz der Klassen zeigt die Entwicklungsphase. In diesem Beispiel befindet sich die Person in Entwicklungsphase I.
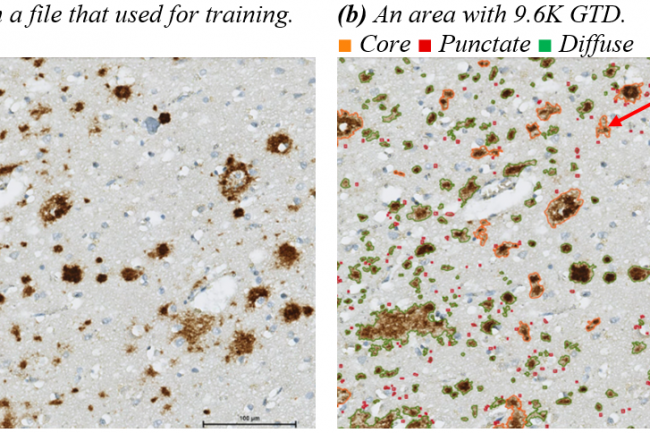
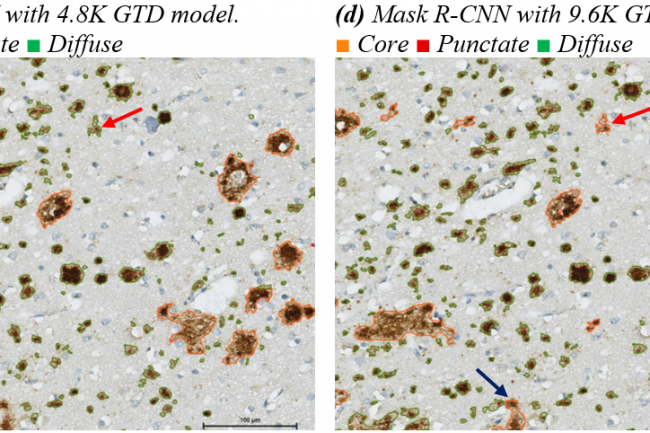
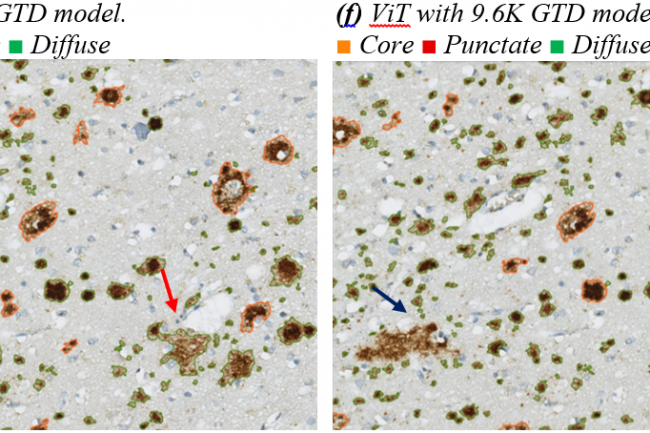
Die Bewertung trainierter KI-Modelle ist wichtig und sollte nicht ausschließlich auf numerischen Ergebnissen beruhen. Visuelle Interpretation der Ergebnisse ist notwendig, um die Zuverlässigkeit des Modells sicherzustellen. In diesem Abschnitt werden visuelle Interpretationen der Ergebnisse vorgestellt. Abbildung (a) zeigt einen bestimmten Bereich ohne Modell oder Modifikationen. Abbildung (b) ist derselbe Bereich mit manuellen Anmerkungen, während die Abbildungen (c) bis (f) die Ergebnisse verschiedener Modelle zeigen. Das HyperAmyNet-Modell (Typ 1) mit 9,6K GTD zeigte die besten Eigenschaften, benötigt jedoch noch mehr Daten und Einstellungen, um sich zu verbessern. Beim Vergleich aller vier Modelle wurde keine punktierte Klasse erkannt, was nicht mit der Menge an GTD zusammenhängt. Eine ausreichende Menge an Daten für die Erkennung eines Objekts beträgt 6110 (62,13%) der trainierten Daten.
xAI Tool
Sie können das xAI Tool in der Software HSA KIT verwenden, um die Entscheidungen bereits trainierter Deep Learning-Modelle oder während des Trainingsprozesses zu verstehen. Sobald Sie ein DL-Modell trainiert haben und es auf die Dateien, z. B. hier Gehirnschnitte, angewendet haben, können Sie die Ergebnisse der Erkennung von Beta-Amyloid-Signalen, insbesondere der Klassen wie der punktierten Klasse, anzeigen lassen. Durch Aktivierung von xAI und Icon-Heatmap können Sie leicht die Pixel in Rot anzeigen, die für Ihr Deep Learning-Modell am wichtigsten sind, um die Klasse punktiert von Beta-Amyloid zu bilden. Alles, was blau ist, zeigt Ihnen, dass das DL-Modell diese Pixel ebenfalls verwendet, um die Klasse punktiert zu bilden, ihnen jedoch nicht viel Priorität einräumt. Auf diese Weise können Sie die Entscheidung bereits trainierter Deep Learning-Modelle sowie während des Trainingsprozesses verstehen.
Die zugrunde liegenden Trainingsdaten und das Trainingsverfahren sowie die Ergebnisse von KI-Modellen bieten das beste Verständnis für ein KI-System. Dieses Wissen erfordert die Fähigkeit, ein trainiertes KI-Modell auf den tatsächlichen Datensatz abzubilden, der verwendet wurde, um es zu trainieren, sowie die Fähigkeit, diese Daten genau zu analysieren. Eine genaue Aufmerksamkeit auf die Daten, die verwendet werden, um ein Modell zu trainieren, ist eine der einfachsten Methoden, um seine Erklärbarkeit zu verbessern. Teams müssen feststellen, woher die Daten zur Schulung eines Algorithmus stammen, ob die Daten Vorurteile enthalten und was während des Designprozesses getan werden kann, um diese Vorurteile zu minimieren. Das xAI Tool in HSA KIT findet den Zielbereich, der ein Signal an einem bestimmten Ort enthält, und es ist eine diskriminative Lokalisierungstechnik, die visuelle Erklärungen für jedes Projekt liefern kann, ohne dass architektonische Änderungen oder Schulungen erforderlich sind.
Durch Aktivierung des „Heatmap“-Symbols in HSA KIT und Auswahl einer Struktur erscheinen die Ergebnisse für diese Struktur in visueller Form.
Die untenstehenden Bilder zeigen die Heatmap der Beta-Amyloid-Klassen. Die warmen Farben (gelb und rot) repräsentieren Bereiche mit höherer Intensität, die vom Modell erkannt wurden, und umgekehrt.
Ein Beispiel für das xAI Tool in HSA KIT, um zu verstehen, warum das Deep Learning-Modell Beta-Amyloid-Signale in die Klasse punktiert klassifiziert. In Rot sehen wir mehrere punktierte Signale, die nahe beieinander liegen, sodass wir die Verteilung innerhalb des Bereichs von 69 Pixeln sehen können. Wir sehen in Rot die Pixel und Formen, die das Deep Learning-Modell beim Aufbau der Klassen punktiert priorisiert hat, sowie Blau, die beim Aufbau der Klassen enthalten sind, aber nicht so wichtig sind. Auf diese Weise verstehen Sie visuell, wo Ihr Deep Learning-Modell bei einer bestimmten Klasse gut abschneidet und wo nicht. Danach können Sie die Metriken überprüfen und entscheiden, wie Sie Ihr Deep Learning-Modell verbessern oder einfach den Weg der Segmentierung und Klassifizierung Ihres Deep Learning-Modells zur Erkennung von Beta-Amyloid-Signalen und Klassifizierung punktiert, Kern, diffus und vaskulär verstehen.
Digitalisierung von histologischen Präparaten und Analyse mit HSA KIT
HSA importiert und arbeitet an „NDPI“-Dateien, die das Ergebnis des Hamamatsu NanoZoomer 2.0 HT-Geräts sind, einem Folien-Scanner. Sie passen perfekt zu HSA KIT.
Wenn Sie keinen Folien-Scanner haben und später einen erwerben möchten, verwenden Sie unsere kostengünstige und erschwingliche Software (HSA SCAN M), um die Folien manuell direkt auf Ihrem Mikroskop zu digitalisieren und manuelle WSI zu erstellen.

In diesem Video können Sie das manuelle Scannen sehen, das eine Folie mit der HSA SCAN-Software in eine Datei umwandelt, die dann von der HSA KIT-Software verwendet werden kann, um trainiert zu werden, und dann automatisch vom trainierten KI-Modell erkannt wird.
Wenn Sie die Folien automatisch scannen möchten, können Sie Ihr Mikroskop auf eine automatische Mikroskopstation (HSA SCAN A) aufrüsten. Dadurch wird Ihr Mikroskop in einen automatischen Scanner für ein kleines Budget und eine hohe Leistung in kurzer Zeit umgewandelt.
Das einzige, was HSA benötigt, sind die Abmessungen Ihres Mikroskops und die Spezifikationen, die Sie hinzufügen möchten, und wir werden Ihnen einen Stand und einen Motor für Ihr Gerät zusenden, der zu Ihrem Mikroskop passt.
Dies wird Ihnen helfen bei:
- Schnelleres Scannen
- Genaueres Scannen
- Zeitersparnis
- Niedriges Budget

Im obigen Video sehen Sie ein Beispiel für einen automatischen Scanner (HSA SCAN A). Zögern Sie nicht, uns für weitere Informationen oder Bestellungen zu kontaktieren.
Für weitere Informationen oder Bestellungen : sales@hs-analysis.com