Einführung
Die IgA-Nephropathie (IgAN), auch bekannt als Berger-Krankheit, ist die weltweit häufigste Glomerulonephritis. Sie ist gekennzeichnet durch die Ablagerung von Immunglobulin A (IgA) in den Glomeruli, was zu Entzündungen und fortschreitender Nierenschädigung führt. Die Krankheit äußert sich auf unterschiedliche Weise und reicht von asymptomatischer Hämaturie bis hin zur Nierenerkrankung im Endstadium (ESRD). Eine frühzeitige und genaue Diagnose sowie die Bewertung prognostisch relevanter Parameter sind entscheidend für eine wirksame Behandlung der IgAN.
Herausforderungen in der diagnostischen Nephropathologie
Die traditionelle Diagnose und Prognose der IgAN beruhen in hohem Maße auf der Nierenbiopsie und der anschließenden histopathologischen Untersuchung. Pathologen werten Biopsien mit Hilfe verschiedener Färbetechniken und Mikroskopie aus, um pathologische Merkmale wie mesangiale Hyperzellularität, segmentale Glomerulosklerose und tubuläre Atrophie zu identifizieren und zu quantifizieren. Dieser Prozess ist arbeitsintensiv, subjektiv und anfällig für Schwankungen zwischen den Beobachtern, was zu uneinheitlichen prognostischen Einschätzungen führen kann.
Die Rolle des Deep Learning in der Nephropathologie
Deep Learning (DL), ein Teilbereich der künstlichen Intelligenz (KI), hat in verschiedenen Bereichen, einschließlich der medizinischen Bildgebung, bemerkenswerte Erfolge bei der Bildanalyse und Mustererkennung erzielt. Convolutional Neural Networks (CNNs), eine Art von Deep-Learning-Architektur, sind aufgrund ihrer Fähigkeit, automatisch zu lernen, besonders gut für die Analyse histopathologischer Bilder geeignet
Deep Learning-basierter Assistent für IgAN
Ein auf Deep Learning basierender Assistent in der diagnostischen Nephropathologie für IgAN zielt darauf ab, den Bewertungsprozess von Nierenbiopsien zu automatisieren und zu verbessern. Ein solches System kann Pathologen unterstützen durch:
- Automatisierung der Merkmalsextraktion: Automatische Identifizierung und Quantifizierung relevanter histopathologischer Merkmale aus digitalisierten Biopsiebildern, wie glomeruläre Läsionen, interstitielle Fibrose und vaskuläre Veränderungen.
- Verringerung der Variabilität: Minimierung der Variabilität zwischen den Beobachtern durch konsistente und reproduzierbare Bewertungen.
- Verbesserung der prognostischen Genauigkeit: Nutzung großer Datensätze zum Erlernen und Vorhersagen komplexer Muster, die mit dem Krankheitsverlauf und den Patientenergebnissen korrelieren.
- Zeiteffizienz: Erhebliche Reduzierung des Zeitaufwands für die Biopsieanalyse, was eine schnellere Diagnose und Behandlungsplanung ermöglicht.
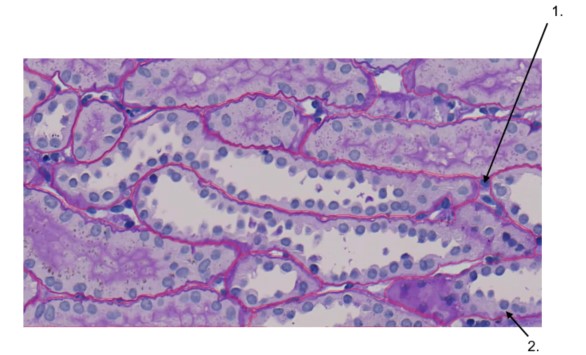
Strukturen
1-Tubulus
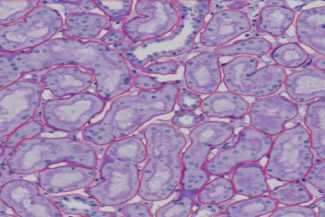
Die Nieren sind essentielle Organe, die Blut filtern, Abfallstoffe entfernen und Flüssigkeiten ausgleichen. In jeder Niere gibt es winzige Strukturen, die Nephrone genannt werden, wobei jedes Nephron einen langen, gewundenen Schlauch, das sogenannte Tubulus, enthält. Die Tubuli spielen eine entscheidende Rolle bei der Filtration, Rückresorption und Sekretion. Sie filtern Abfallstoffe und überschüssige Substanzen aus dem Blut, reabsorbieren essenzielle Substanzen wie Wasser, Glukose und Salze zurück in den Blutkreislauf und sondern zusätzliche Abfallprodukte in die Flüssigkeit ab, die zu Urin wird. Die Tubuli bestehen aus mehreren Teilen: dem proximalen konvuluten Tubulus (PCT), wo die meiste Rückresorption erfolgt, der Henle-Schleife, die hilft, den Urin zu konzentrieren, dem distalen konvuluten Tubulus (DCT), der die Rückresorption und Sekretion feinjustiert, und dem Sammelrohr, wo der Urin weiter konzentriert wird, bevor er in das Nierenbecken und dann in die Blase abfließt. Die Analyse der Nierentubuli ist wichtig zur Beurteilung der Nierenfunktion, zur Erkennung von Erkrankungen wie akuter tubulärer Nekrose oder chronischer Nierenerkrankung und zur Überwachung der Wirksamkeit von Behandlungen bei Nierenerkrankungen. Daher ist das Verständnis der Funktion und Gesundheit der Tubuli entscheidend für die Bewertung der allgemeinen Nierengesundheit.
2-Glomerulus
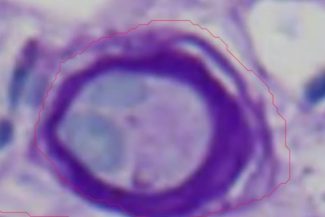
Ein wesentlicher Bestandteil jedes Nierennephrons ist der Glomerulus, der als erster Ort der Blutfiltration dient. Der Glomerulus ist ein Netzwerk aus mikroskopisch kleinen Kapillaren, das von der Bowman-Kapsel umgeben ist und das Blut filtert, indem größere Moleküle wie Proteine und Blutkörperchen zurückgehalten werden, während Wasser, Salze, Glukose und Abfallstoffe wie Harnstoff durch die porösen Membranen strömen dürfen. Das durch diesen Filterprozess erzeugte Filtrat verwandelt sich schließlich in Urin, wenn es das Nephron passiert. Ein wichtiger Indikator für die Nierengesundheit ist die glomeruläre Filtrationsrate (GFR), die angibt, wie effizient der Glomerulus das Blut filtert. Durch Prozesse wie das Renin-Angiotensin-Aldosteron-System trägt der Glomerulus auch zur Regulierung bei. Proteinurie und Hämaturie sind Hinweise auf Erkrankungen, die den Glomerulus betreffen, wie Glomerulonephritis oder diabetische Nephropathie. Diese Erkrankungen können die Filtration beeinträchtigen. Daher spielt die Analyse der Glomerulusgesundheit eine entscheidende Rolle bei der Diagnose und Behandlung von Nierenerkrankungen. Tests wie die Urinanalyse, die Berechnung der GFR und Nierenbiopsien liefern wichtige Informationen in diesem Zusammenhang.
3-Peritubuläre Kapillaren (PTC)
Das Netzwerk aus winzigen Blutgefäßen in den Nieren, bekannt als peritubuläre Kapillaren (PTC), umgibt die Nierentubuli und ist entscheidend für die Urinproduktion und Blutfiltration. Diese Kapillaren, die aus der efferenten Arteriole hervorgehen, unterstützen den chemischen Austausch zwischen der tubulären Flüssigkeit und dem Blut. Sie sind notwendig, um sicherzustellen, dass wichtige Stoffe wie Wasser, Glukose, Aminosäuren und Elektrolyte nicht im Urin verschwendet werden, indem sie wieder in den Blutkreislauf aufgenommen werden. Darüber hinaus helfen die PTCs, Abfallstoffe und überschüssige Ionen aus dem Blut in die tubuläre Flüssigkeit zu entfernen und so das chemische Gleichgewicht zu erhalten. Die dünnen Wände der PTCs erleichtern den einfachen Stofftransport und ermöglichen einen effektiven Austausch aufgrund ihrer Nähe zu den Tubuli. Sie versorgen die Tubuluszellen zudem mit notwendiger Nahrung und Sauerstoff. Dieser effektive Austauschmechanismus ist entscheidend für die Regulierung des Flüssigkeits- und Elektrolytgleichgewichts sowie des Säure-Basen-Gleichgewichts im Körper. Schäden an diesen Kapillaren können die Nierenfunktion beeinträchtigen und zu Erkrankungen führen. Solche Schäden werden häufig durch Erkrankungen wie Diabetes und Hypertonie verursacht. Daher ist die Analyse der PTC-Funktion entscheidend für die Diagnose und Behandlung nierenspezifischer Störungen, wobei Blut- und Urintests Informationen über den Zustand der Nieren und ihre Rolle in der Homöostase liefern.
4-Arterielle
5-Periglomeruläre Kapillaren (PGC) oder Nerven
Die sympathischen Fasern, die den Großteil der Nerven der Nieren ausmachen, sind entscheidend für die Kontrolle der Nierenfunktion. Durch die Regulierung der Kontraktion und Entspannung der afferenten und efferenten Arteriolen beeinflussen diese Nerven den Blutfluss in den Nieren, was die glomeruläre Filtrationsrate (GFR) und den gesamten Blutdruck beeinflusst. Darüber hinaus steuern sie die Freisetzung von Renin durch die juxtaglomerulären Zellen, welches ein wesentlicher Bestandteil des Renin-Angiotensin-Aldosteron-Systems (RAAS) ist und zur Regulierung des Flüssigkeits- und Blutdrucks beiträgt. Zudem unterstützen die Nerven die Nieren dabei, auf systemische Umstände wie Stress oder Dehydration zu reagieren, indem sie die Filtrations- und Rückresorptionsprozesse der Nieren anpassen. Diese Nerven sind für die Aufrechterhaltung des Flüssigkeits- und Elektrolytgleichgewichts sowie der allgemeinen Homöostase unerlässlich; jede Fehlfunktion oder Verletzung kann die Nierenfunktion beeinträchtigen und Erkrankungen wie Hypertonie und chronische Nierenerkrankungen verschärfen.
6-Interstitium
In der Nierenanalyse haben wir das Interstitium als Hintergrund des annotierten Objekts markiert.

Implementierung und Vorteile
Um einen auf Deep Learning basierenden Assistenten zu entwickeln, werden hochauflösende Bilder von Nierenbiopsien von erfahrenen Pathologen annotiert, um einen gekennzeichneten Datensatz zu erstellen. Dieser Datensatz wird verwendet, um CNNs zu trainieren, die lernen, prognostisch relevante Merkmale zu erkennen und zu quantifizieren. Fortschrittliche Modelle können auch klinische Daten und andere Biomarker integrieren, um umfassende prognostische Einblicke zu bieten.
Der Einsatz eines solchen Systems in der klinischen Praxis bietet mehrere Vorteile:
- Verbesserte diagnostische Präzision: Erhöhte Genauigkeit bei der Erkennung und Quantifizierung pathologischer Merkmale.
- Standardisierung: Standardisierte Bewertungen über verschiedene Institutionen und Pathologen hinweg.
- Erweiterte prognostische Vorhersagen: Bessere Vorhersagemodelle für Patientenergebnisse, die bei der personalisierten Behandlungsplanung helfen.
- Bildungswerkzeug: Dient als Trainingshilfe für neue Pathologen, indem es einen Referenzstandard für die Bewertung bereitstellt.
Dateien
- IgA_PAS_008.czi, Szene 1
- IgA_PAS_008.czi, Szene 2
- IgA_PAS_008.czi, Szene 3
- IgA_PAS_009.czi, Szene 1
- IgA_PAS_009.czi, Szene 3


| Dateiname | Projekt | Struktur | Anzahl Annotationen | Struktur | Anzahl Annotationen | Struktur | Anzahl Annotationen | Struktur | Anzahl Annotationen | Struktur | Anzahl Annotationen |
|---|---|---|---|---|---|---|---|---|---|---|---|
| PAS_008.czi Szene 1 | Nierenanalyse | Tubulus | 917 | Glomerulus | 18 | PTC | 1510 | Arterille | 26 | Nerven | 93 |
| PAS_008.czi Szene 2 | Nierenanalyse | Tubulus | 1436 | Glomerulus | 29 | PTC | 759 | Arterille | 17 | Nerven | 43 |
| PAS_008.czi Szene 3 | Nierenanalyse | Tubulus | 707 | Glomerulus | 8 | PTC | 850 | Arterille | 12 | Nerven | 46 |
| PAS_009.czi Szene 1 | Nierenanalyse | Tubulus | 1096 | Glomerulus | 20 | PTC | 1568 | Arterille | 38 | Nerven | 102 |
| PAS_009.czi Szene 3 | Nierenanalyse | Tubulus | 884 | Glomerulus | 9 | PTC | 1724 | Arterille | 125 | Nerven | 41 |


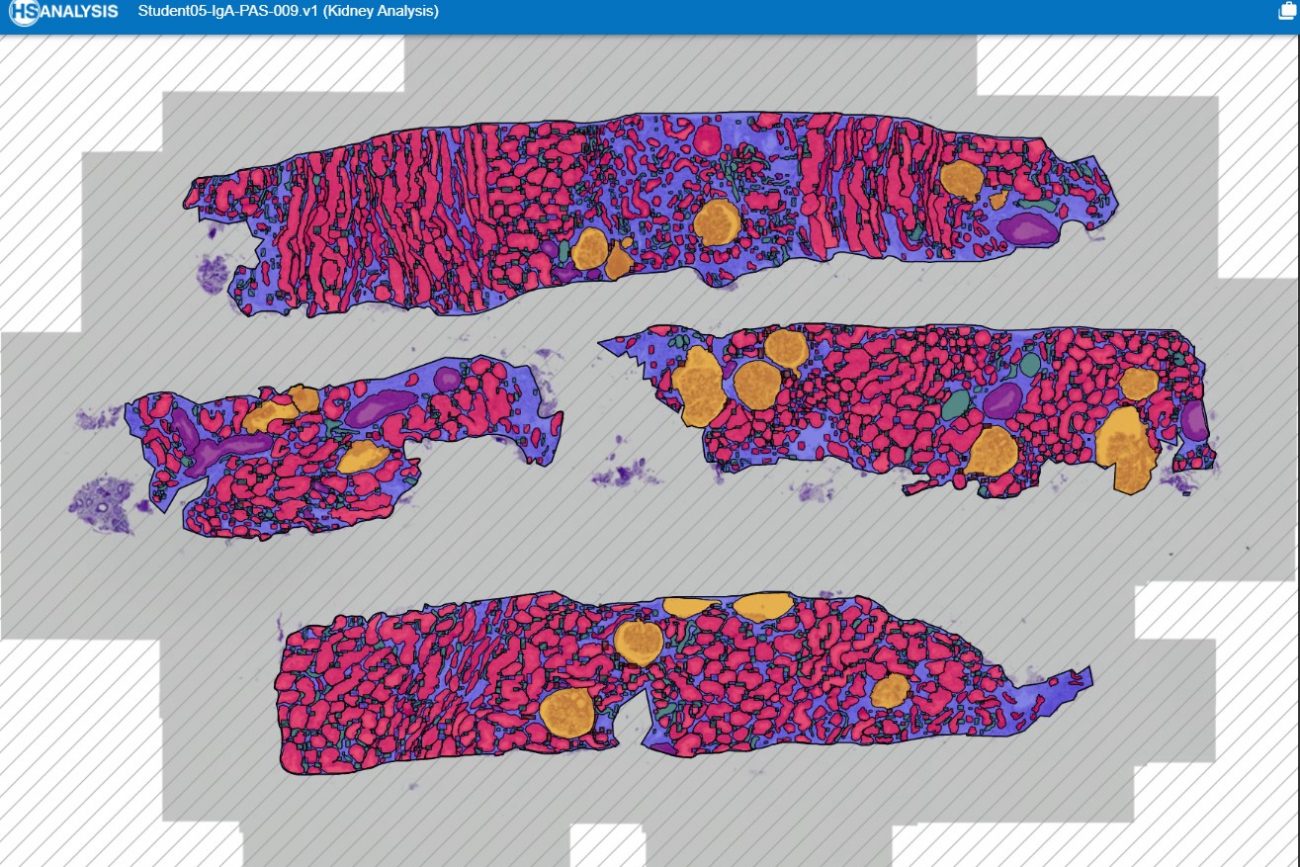
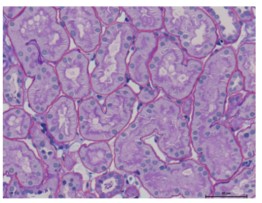
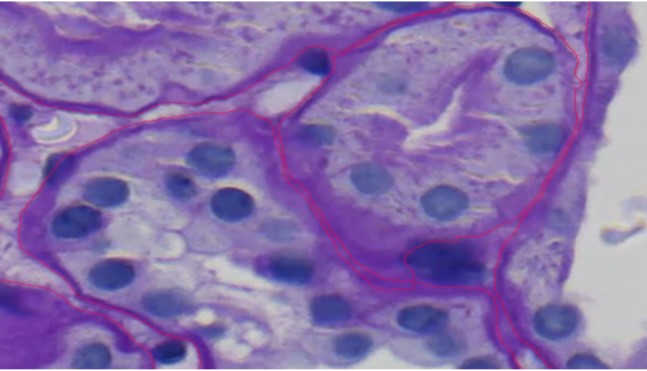
this image shows tubulus and PTC and how they connected


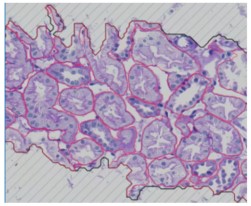
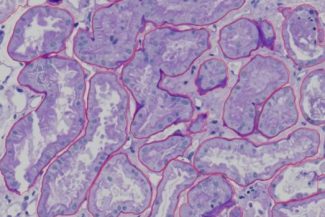
this image it show the all structures that we annotated


Neuronales Netz
Ein neuronales Netz für Deep Learning besteht aus Schichten von Neuronen: Eingabe-, versteckte und Ausgabeschichten. Jedes Neuron wendet eine lineare Transformation auf seine Eingaben an, gefolgt von einer nicht-linearen Aktivierungsfunktion. Das Netz wird mithilfe von Forward Propagation trainiert, um Vorhersagen zu treffen, und Backpropagation, um die Gewichte zu aktualisieren und eine Verlustfunktion zu minimieren, z. B. die Kreuzentropie für Klassifizierungsaufgaben. Optimierungsalgorithmen wie Adam passen diese Gewichte an, um die Genauigkeit zu verbessern. Regularisierungstechniken wie Dropout helfen, eine Überanpassung zu verhindern. Mit Frameworks wie TensorFlow können Sie Modelle für verschiedene Anwendungen effektiv erstellen, trainieren und bewerten.
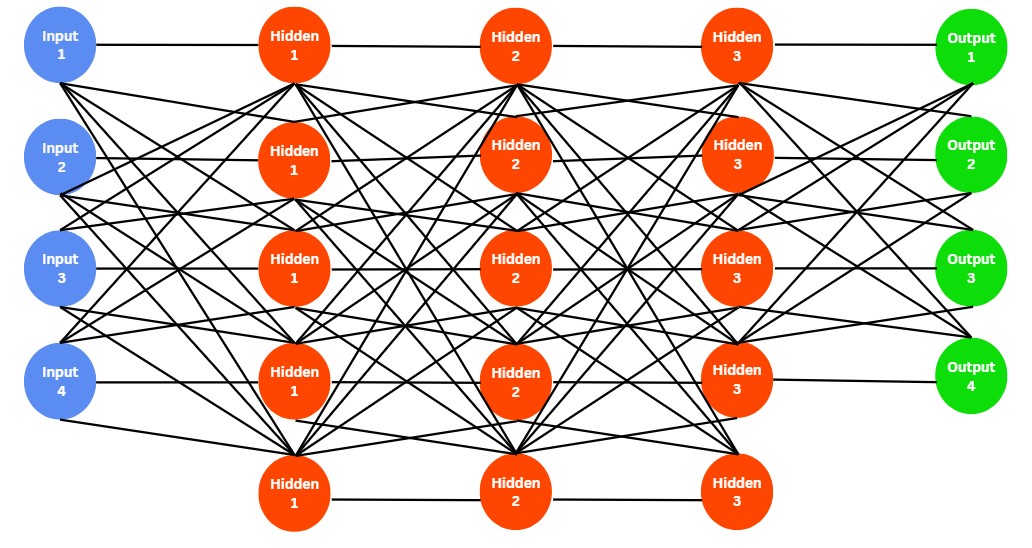
Struktur:
- Eingabeschicht (blaue Kreise auf der linken Seite):
- Es gibt 4 Eingabeknoten mit den Bezeichnungen „Eingabe 1“, „Eingabe 2“, „Eingabe 3“ und „Eingabe 4“.
- Diese Knoten stellen die Merkmale oder Variablen dar, die in das neuronale Netz eingespeist werden.
- Ausgeblendete Schichten (orangefarbene Kreise in der Mitte):
- Das Netzwerk hat 3 ausgeblendete Schichten, die jeweils 5 Knoten mit den Bezeichnungen „Ausgeblendet 1“, „Ausgeblendet 2“ und „Ausgeblendet 3“ enthalten.
- Diese Schichten führen Zwischenberechnungen und -transformationen an den Daten durch.
- Jeder Knoten in einer Schicht ist mit jedem Knoten in der nachfolgenden Schicht verbunden, wodurch ein dichtes (vollständig verbundenes) Netzwerk entsteht.
- Ausgabeschicht (grüne Kreise auf der rechten Seite):
- Es gibt 4 Ausgabeknoten, die mit „Ausgabe 1“, „Ausgabe 2“, „Ausgabe 3“ und „Ausgabe 4“ bezeichnet sind.
- Diese Knoten erzeugen die endgültige Ausgabe des neuronalen Netzes, die Vorhersagen oder Klassifizierungen auf der Grundlage der Eingabedaten sein können.
Verbindungen:
- Linien:
- Die Linien zwischen den Knoten stellen die Verbindungen (Kanten) zwischen den Neuronen dar.
- Jeder Verbindung ist ein Gewicht zugeordnet, das während des Trainings angepasst wird, um den Fehler in der Ausgabe zu minimieren.
- Diese Gewichte bestimmen, wie viel Einfluss die Ausgabe eines Knotens auf die Eingabe des nächsten Knotens hat
Wie es funktioniert:
Vorwärtspropagation:
-
- Die Eingangsdaten werden in die Eingabeschicht eingespeist und dann schichtweise durch das Netzwerk weitergeleitet, bis sie die Ausgabeschicht erreichen.
- Jeder Knoten in einer Schicht wendet eine mathematische Funktion (oder Aktivierungsfunktion) auf seine Eingaben an, um ein Ergebnis zu produzieren, das dann an die nächste Schicht weitergegeben wird.
- Training:
- Während des Trainings passt das Netzwerk die Gewichte der Verbindungen basierend auf der Differenz zwischen der vorhergesagten Ausgabe und der tatsächlichen Ausgabe an.
- Diese Anpassung erfolgt typischerweise durch einen Prozess namens Rückpropagation, bei dem der Fehler durch iteratives Aktualisieren der Gewichte minimiert wird.
Wichtige Punkte:
-
-
- Komplexität: Das Netzwerk ist in der Lage, komplexe Muster zu lernen, dank der vielen versteckten Schichten und der vollständig verbundenen Architektur.
- Vielseitigkeit: Dieser Typ von neuronalen Netzwerken kann für eine Vielzahl von Aufgaben verwendet werden, wie Klassifikation, Regression und komplexere Aufgaben wie Bild- und Spracherkennung.
-
Was ist Deep Learning?
Schritt 1: Das Problem erkennen
Der erste Schritt im Deep Learning-Prozess besteht darin, das Problem, das Sie lösen möchten, klar zu verstehen. Dazu gehört es, die spezifischen Aufgaben, gewünschten Ergebnisse und Einschränkungen im Zusammenhang mit dem Problem zu identifizieren. Es ist entscheidend, den geschäftlichen Kontext und die Anforderungen zu erfassen, um sicherzustellen, dass die Lösung mit den organisatorischen Zielen übereinstimmt. Durch eine gründliche Definition des Problems schaffen Sie eine solide Grundlage, die die nachfolgenden Schritte im Deep Learning-Workflow leitet.
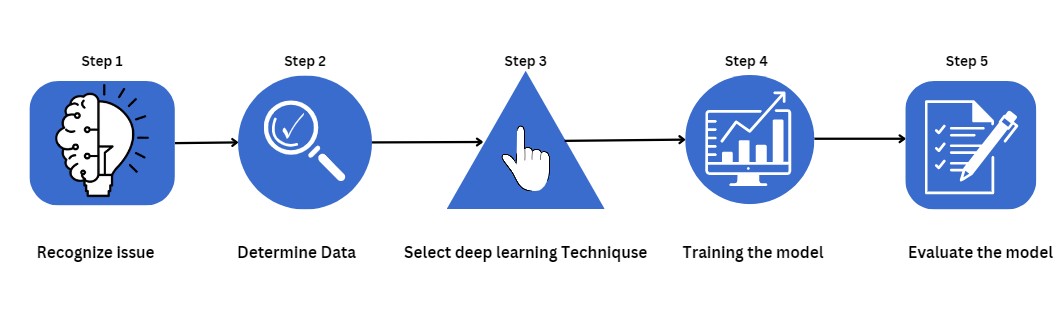
Schritt 2: Daten bestimmen
Sobald das Problem gut definiert ist, besteht der nächste Schritt darin, die notwendigen Daten zu identifizieren und zu sammeln. Dies umfasst das Sammeln relevanter Datensätze aus verschiedenen Quellen, wobei sichergestellt werden muss, dass die Daten sowohl in ausreichender Menge als auch von hoher Qualität sind. Daten sind das Rückgrat jedes Deep Learning-Modells, und ein umfassender Datensatz ist entscheidend für das Training eines genauen und robusten Modells. Eine ordnungsgemäße Datensammlung schafft die Grundlage für eine effektive Datenvorbereitung und Modelltraining.
Schritt 4: Modell trainieren
Eine entscheidende Phase im Deep Learning-Prozess ist das Modelltraining. Dazu wird die Datenmenge in Trainings- und Validierungsdatensätze aufgeteilt und das Modell mithilfe des Trainingssatzes trainiert. Um die Verlustfunktion zu minimieren, werden Optimierungsmethoden und Backpropagation verwendet, um die Gewichte des Modells während des Trainings anzupassen. Um die Leistung des Modells zu überwachen und Überanpassung (Overfitting) zu vermeiden, wird der Validierungsdatensatz verwendet. Das Ergebnis eines erfolgreichen Trainings ist ein Modell mit optimalen Gewichten, das sowohl bei den Trainings- als auch den Validierungsdaten gut abschneidet.
Schritt 3: Geeignete Deep Learning-Techniken auswählen
Nach dem Sammeln der Daten verlagert sich der Fokus auf die Auswahl geeigneter Deep Learning-Methoden und Modellarchitekturen. Verschiedene Techniken sind für unterschiedliche Herausforderungen erforderlich. Während beispielsweise rekurrente neuronale Netze (RNNs) besser für sequentielle Daten geeignet sind, werden Convolutional Neural Networks (CNNs) häufig für Bildklassifizierungsaufgaben eingesetzt. Eine effektive Problemlösung erfordert die Bewertung mehrerer Deep Learning-Methoden und die Auswahl der passenden Modellarchitektur.
Schritt 5: Das Modell bewerten
Das Testen des Modells zur Beurteilung seiner Leistung anhand hypothetischer Daten ist der letzte Schritt. Dies beinhaltet die Bewertung der Generalisierungsfähigkeit des Modells mit einem unabhängigen Testdatensatz. Die prognostizierte Leistung des Modells unter realen Bedingungen wird mithilfe geeigneter Leistungskennzahlen wie Genauigkeit, Präzision und Rückruf gemessen. Das Testen stellt sicher, dass das Modell zuverlässig ist und bereit für den Einsatz.
Was ist Maschinelles Lernen (ML)?
Wir können die Phasen des ML-Prozesses in 5 Schritte unterteilen, wie im Flussdiagramm unten dargestellt.
Daten sammeln (1. Schritt):
Dies ist die anfängliche Phase, in der Daten, die für das Problem relevant sind, gesammelt werden. Die Daten können aus verschiedenen Quellen stammen, wie Datenbanken, Sensoren oder externen Datensätzen. Die Qualität und Menge der Daten sind entscheidend, da sie die Leistung des Modells direkt beeinflussen.
Datenaufbereitung (2. Schritt):
Auch als Datenvorverarbeitung bekannt, umfasst dieser Schritt das Reinigen und Transformieren der Rohdaten in ein brauchbareres Format. Dies kann das Umgang mit fehlenden Werten, das Korrigieren von Inkonsistenzen, das Normalisieren der Daten und das Transformieren in eine Struktur beinhalten, die für das Modellieren geeignet ist.
Modellbildung (3. Schritt):
In dieser Phase wird ein maschinelles Lernmodell ausgewählt und mit den vorverarbeiteten Daten trainiert. Dies beinhaltet die Wahl des richtigen Algorithmus (z.B. Regression, Entscheidungsbäume, neuronale Netze) und das Anpassen der Parameter zur Optimierung der Leistung. Das Modell lernt Muster aus den Daten, um Vorhersagen oder Entscheidungen zu treffen.
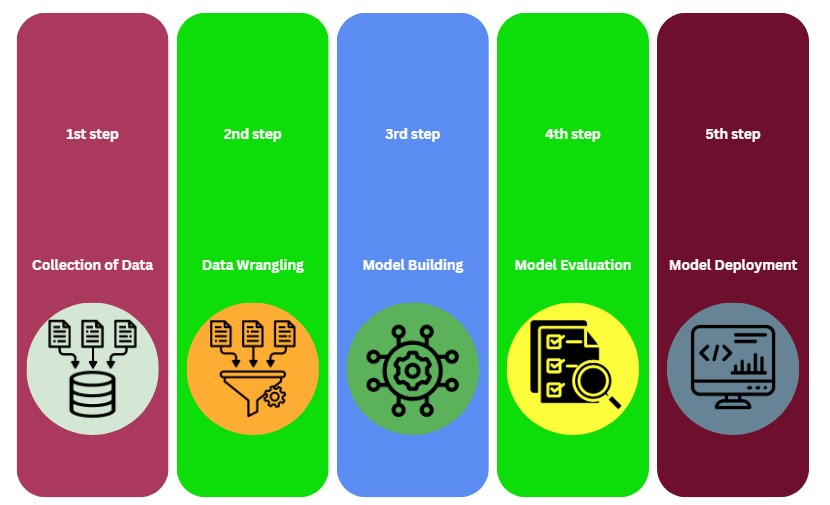
Modellbewertung (4. Schritt):
Nachdem das Modell erstellt wurde, muss es bewertet werden, um seine Genauigkeit und Generalisierungsfähigkeit sicherzustellen. Dies erfolgt durch das Testen des Modells mit einem separaten Datensatz (der nicht im Training verwendet wurde) und die Verwendung verschiedener Metriken (z.B. Genauigkeit, Präzision, Rückruf, F1-Score), um seine Leistung zu messen.
Modellbereitstellung (5. Schritt):
Sobald das Modell validiert ist und gut funktioniert, wird es in einer Produktionsumgebung bereitgestellt. Hier wird das Modell in realen Anwendungen verwendet, um Vorhersagen zu treffen oder Entscheidungsprozesse zu automatisieren. Zur Bereitstellung gehört auch die Überwachung der Modellleistung über die Zeit, um sicherzustellen, dass es genau bleibt, und das Aktualisieren des Modells nach Bedarf.
First AI Model for Tubulus
IgA_PAS_008.czi Szene 1
Das erste Training, das ich mit der Datei IgA_PAS_008.czi Szene 1 durchgeführt habe, verwendete ein KI-Modell für die Annotationen. Die Ergebnisse sind gut, und das Modell zeigt auf dem Bild, dass die KI in der Lage ist, große Objekte zu annotieren, diese zu trennen und kleine Bereiche zwischen den Objekten auszuschließen. Das gesamte Objekt wurde annotiert, wie Sie in der zweiten Notiz sehen können. Das Objekt hat eine andere Farbe, aber die KI hat es als ein einziges Objekt annotiert, was korrekt ist.
Danach habe ich eine weitere Region validiert, und es sieht in diesem Bild unten so aus, dass die KI ein komplexes Objekt annotieren kann.
PAS_008.czi Szene 2
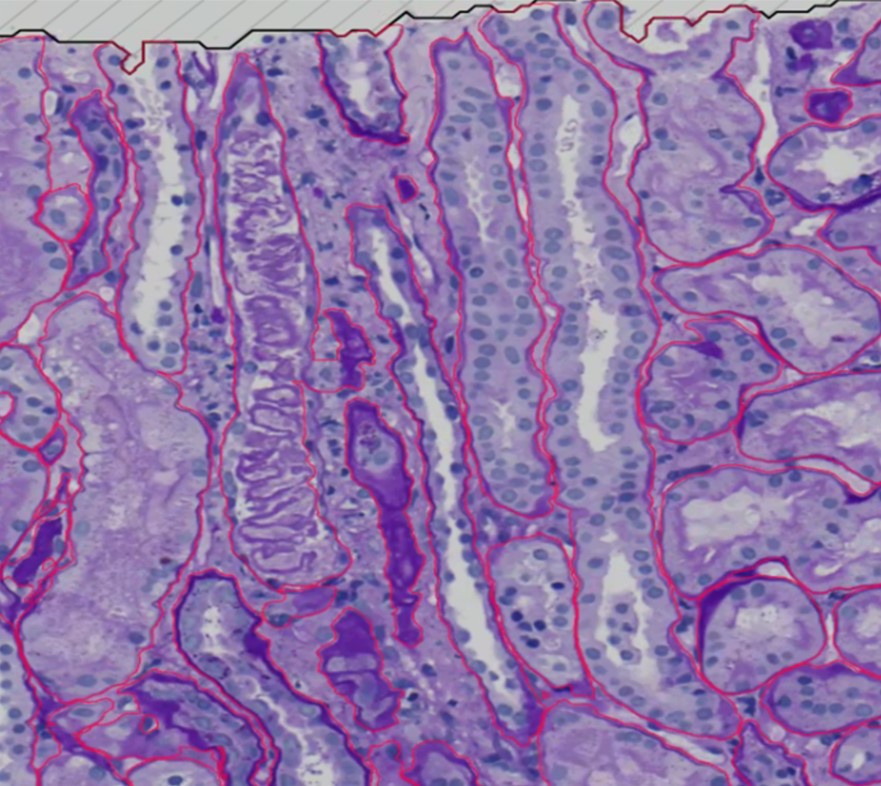
Die Annotationen des KI-Modells im bereitgestellten histologischen Bild scheinen von hoher Qualität zu sein. Die roten Linien verfolgen genau die Grenzen der Zellstrukturen und zeigen eine gute Übereinstimmung mit den natürlichen Kanten. Die Annotationen decken die meisten sichtbaren Strukturen ab, was auf Vollständigkeit hindeutet. Die Konsistenz wird im gesamten Bild beibehalten, wobei ähnliche Strukturen ähnlich umrandet werden. Die Klarheit wird durch die Verwendung dünner Linien gewahrt, die keine wichtigen Details verdecken, und die Annotationen folgen spezifisch den Konturen der Strukturen, was die Fähigkeit des Modells widerspiegelt, feine Details zu erkennen. Insgesamt sind die Annotationen genau, vollständig, konsistent, klar und spezifisch.
Die von dem KI-Modell erzeugten Annotationen zeigen eine hervorragende Qualität in diesem Nahaufnahmefoto. Die roten Linien halten sich eng an die Grenzen der Zellstrukturen und demonstrieren ein hohes Maß an Präzision bei der Identifizierung der Zellränder. Sie sind gut an die natürlichen Kurven angepasst und scheinen jede sichtbare Struktur abgegrenzt zu haben, was auf eine gründliche Erkennung hinweist. Die Zuverlässigkeit wird durch den einheitlichen Annotationstil gewährleistet, der jede Zelle auf vergleichbare Weise definiert. Dünne rote Linien werden verwendet, ohne die inneren Merkmale zu verdecken, um die Klarheit zu bewahren. Die Annotationen sind detailliert und legen großen Wert auf die feinen Merkmale der Zellränder, was darauf hindeutet, dass das Modell in der Lage ist, komplexe Veränderungen in der Zellform genau darzustellen. Alles in allem sind die Annotationen präzise, umfassend, kohärent, eindeutig und zielgerichtet.
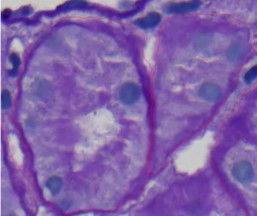
Hier sehen Sie eine hervorragende Annotation, die die KI durchgeführt hat. Sie annotiert das gesamte Objekt und trennt es von einem anderen. Die Qualität ist hier sehr gut; die KI hat die Zellkerne vom linken Objekt ausgeschlossen.
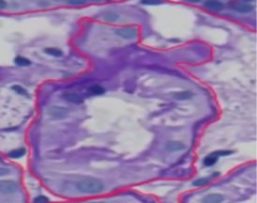
In diesem Bild hat das KI-Modell das gesamte Objekt nicht vollständig annotiert und einige Teile unmarkiert gelassen. Diese partielle Annotation könnte durch Grenzunschärfe bedingt sein, bei der das Modell Schwierigkeiten hat, klare Kanten in Regionen mit niedrigem Kontrast zu unterscheiden. Darüber hinaus verlässt sich das Modell auf Vertrauensschwellenwerte, und wenn sein Vertrauen in bestimmte Bereiche niedrig ist, vermeidet es möglicherweise das Markieren dieser Bereiche, um Fehler zu reduzieren. Einschränkungen in den Trainingsdaten, wie unzureichende Beispiele ähnlicher Strukturen, können zu unvollständiger Erkennung führen. Die interne Komplexität des Objekts, mit unterschiedlichen Texturen und Intensitäten, könnte das Modell ebenfalls verwirren und es erschweren, die genauen Grenzen zu bestimmen. Schließlich können algorithmische Einschränkungen die Fähigkeit des Modells beeinträchtigen, mit unregelmäßigen Formen oder fragmentierten Erscheinungen umzugehen. Das Verständnis dieser Faktoren kann dabei helfen, das KI-Modell zu verfeinern, um dessen Annotationgenauigkeit und Vollständigkeit in zukünftigen Iterationen zu verbessern.
PAS_008.czi Szene 3
In dieser Datei sehen Sie auf diesem Bild die Annotationen der KI, die sehr gut annotiert sind, und das Objekt hat eine hohe Qualität.
In den beiden Bildern unten sehen Sie, dass die KI das gesamte Objekt nicht annotiert hat. Ich habe die Validierungseinstellungen geändert und den Vertrauensschwellenwert für erkannte Objekte von 0,5 auf 0,3 gesenkt. Das bedeutet, dass bei einer Senkung des Vertrauensniveaus die Qualität der Annotationen nicht so gut ist wie im linken Bild oder das gesamte Objekt nicht annotiert wird, wie im rechten Bild zu sehen ist.

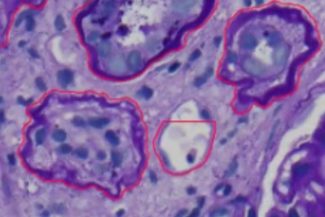
PAS_009.czi Szene 1
- Zuerst haben wir diesen seltsamen Bereich, der von der KI annotiert wurde. Die Qualität der Annotationen ist gut, und alle Tubuli innerhalb des Rechtecks sind annotiert.
- Wie Sie in diesen beiden Bildern sehen können, wurden die PTC als Tubuli annotiert.
PAS_009.czi Szene 2
- Wir haben diese Datei nicht annotiert, aber ich werde die KI auf diese Datei anwenden, um zu sehen, wie die Annotationen ausfallen könnten.

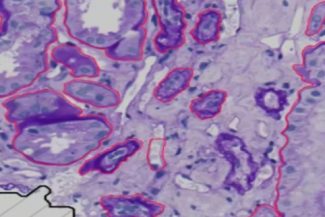
PAS_009.czi Szene 3
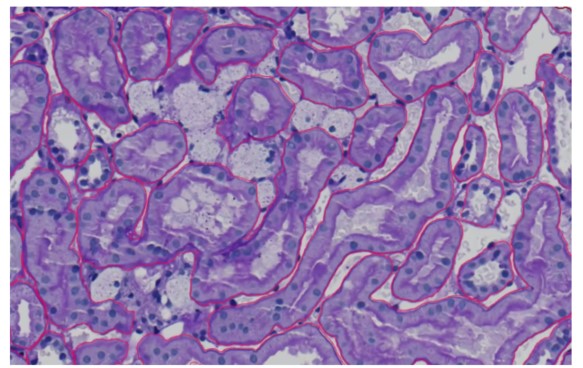
Dieses Bild scheint ein histologischer Schnitt zu sein, der gefärbt und unter einem Mikroskop betrachtet wurde. Es zeigt wahrscheinlich Gewebestrukturen mit zellulären und extrazellulären Komponenten. Die roten Linien umreißen spezifische Bereiche, die wahrscheinlich Regionen von Interesse markieren, die unterschiedliche Gewebekompartimente oder spezifische zelluläre Formationen darstellen könnten. Die Bildqualität ist klar, mit deutlicher Färbung, die eine Unterscheidung verschiedener Zelltypen und Strukturen ermöglicht. Die Anzahl der markierten Bereiche deutet auf eine detaillierte Analyse hin, möglicherweise für diagnostische oder Forschungszwecke, und hebt zahlreiche Regionen innerhalb der Probe hervor. Die Gesamtauflösung ist ausreichend, um zelluläre Details zu beobachten, was das Bild für eine präzise histopathologische Bewertung wertvoll macht.
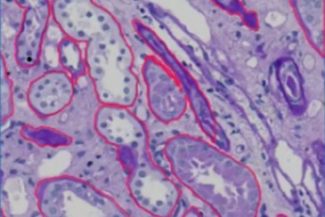
Dieses Bild zeigt einen zweiten gefärbten und mikroskopisch betrachteten histologischen Schnitt, wahrscheinlich bei unterschiedlicher Vergrößerung oder in einem anderen Bereich. Die verschiedenen Merkmale des Gewebes werden durch die roten Umrisse angezeigt. Diese Strukturen ähneln Tubuli oder Drüsenformen, vermutlich aus einer Niere oder einem ähnlichen Drüsenorgan. Aufgrund der effizienten Färbung ist die Bildqualität ausgezeichnet und ermöglicht eine einfache Identifizierung von Zellkernen und anderen zellulären Elementen. Es gibt auch eine deutliche Unterscheidung zwischen zellulären und extrazellulären Komponenten. Die Anzahl der angegebenen Strukturen deutet auf eine sorgfältige Methode hin, um bestimmte Regionen von Interesse hervorzuheben, was auf eine gründliche Untersuchung zu Forschungs- oder Diagnosezwecken hindeutet. Die Gewebearchitektur ist dank der außergewöhnlichen Auflösung in großem Detail sichtbar, was das Bild zu einem unverzichtbaren Werkzeug für die histopathologische Analyse macht.
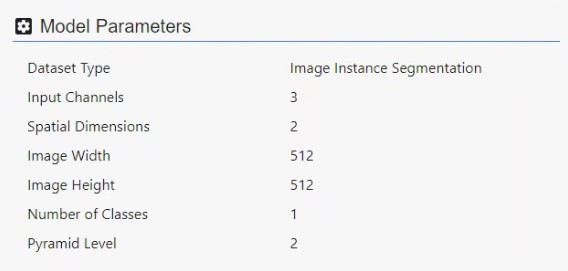
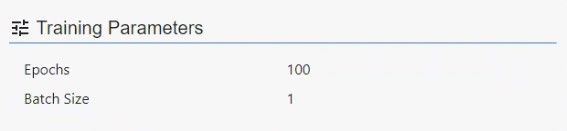
Die Parameter, die wir beim Training des Modells verwendet haben

Seconed Model
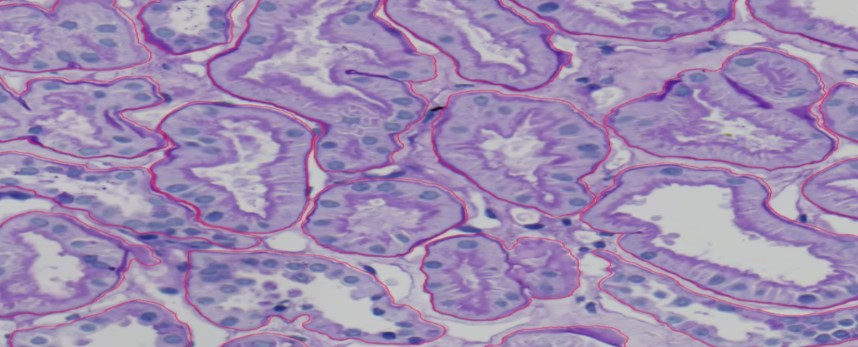
PAS_008.czi Szene 1
In diesen beiden Bildern sehen Sie die hohe Qualität der Annotationen durch die KI. Bei diesem Modell haben wir die Anzahl der Epochen erhöht und die Batch-Größe von 2 auf 1 geändert.
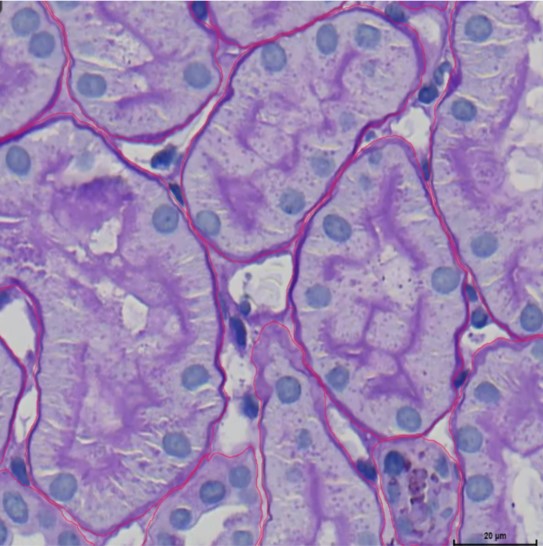
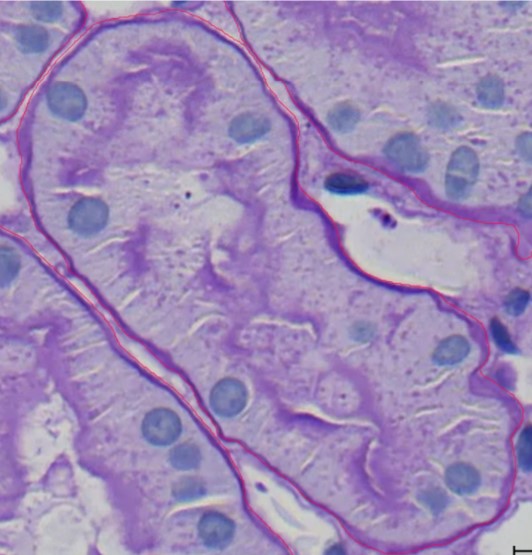
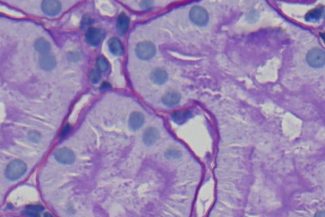
Die Qualität ist insgesamt gut, aber an einigen Stellen sehen Sie, dass die Trennungen zwischen zwei Objekten nicht vollständig sind, wie Sie im Bild unten sehen können. Dennoch hat die KI die Objekte wirklich gut annotiert; sie hat die Zellkerne ausgeschlossen und alle Hauptstrukturen markiert. Sie hat das Hauptgerüst zwischen den Tubuli und den peritubulären Kapillaren (PTC) gut dargestellt.
PAS_008.czi Szene 2
Dieses Bild scheint eine mikroskopische Ansicht einer Gewebeprobe zu zeigen, die wahrscheinlich mit einer Methode wie Hämatoxylin und Eosin (H&E) gefärbt wurde, um zelluläre Strukturen hervorzuheben. Die tiefvioletten Bereiche stellen Zellkerne dar, während die helleren Violetttöne das Zytoplasma und andere Gewebekomponenten darstellen. Die roten Linien, die über das Bild gelegt sind, zeigen an, dass ein KI-Werkzeug verwendet wurde, um spezifische Strukturen innerhalb des Gewebes zu annotieren. Diese Annotationen heben typischerweise wichtige Regionen von Interesse hervor, wie Zellgrenzen oder Bereiche, die auf pathologische Veränderungen hinweisen. Die Präzision der Annotationen deutet darauf hin, dass das KI-Modell in der Lage ist, komplexe biologische Strukturen präzise zu erkennen und abzugrenzen, was für Aufgaben wie histopathologische Analysen von entscheidender Bedeutung ist. Die Fähigkeit der KI, diese Merkmale genau zu annotieren, kann Pathologen bei der Diagnose von Krankheiten unterstützen und sicherstellen, dass subtile morphologische Veränderungen nicht übersehen werden. Diese Kombination aus KI und Histologie veranschaulicht, wie Technologie traditionelle medizinische Praktiken ergänzen kann, was zu effizienteren und genaueren Diagnosen führt.
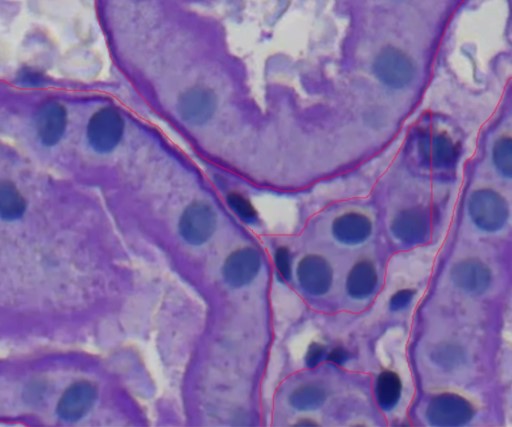
Wie Sie sehen können, zeigt dieses Bild eine mikroskopische Ansicht einer Gewebeprobe, die mit Hämatoxylin und Eosin (H&E) gefärbt wurde. Dabei werden Zellkerne tiefviolett und das Zytoplasma in helleren Violetttönen hervorgehoben. Die roten Linien sind KI-generierte Annotationen, die Zellgrenzen und wichtige Strukturen präzise umreißen. Die Genauigkeit dieser Annotationen demonstriert die Fähigkeit der KI in der histopathologischen Analyse und unterstützt die Krankheitsdiagnose durch zuverlässige und konsistente Identifizierung der Zellkomponenten. Diese Integration von KI verbessert die Effizienz und Genauigkeit medizinischer Diagnosen.
PAS_008.czi Szene 3
Dieses Bild zeigt eine vergrößerte Ansicht einer Gewebeprobe, die mit Hämatoxylin und Eosin (H&E) gefärbt wurde, wobei Zellkerne in Dunkelviolett und das umgebende Zytoplasma in helleren Schattierungen erscheinen. Die roten Linien, die über das Bild gelegt sind, stellen KI-generierte Annotationen dar, die präzise die Grenzen einzelner Zellen markieren. Diese genauen Abgrenzungen durch die KI zeigen ihre hohe Leistungsfähigkeit bei der Identifizierung und Umrisszeichnung zellulärer Strukturen im Gewebe. Solche detaillierten und konsistenten Annotationen sind entscheidend für die histopathologische Analyse, da sie die Erkennung von Anomalien erleichtern und eine genaue Krankheitsdiagnose unterstützen. Die Integration der KI-Technologie in diesem Kontext verbessert die Effizienz und Zuverlässigkeit medizinischer Bewertungen erheblich.
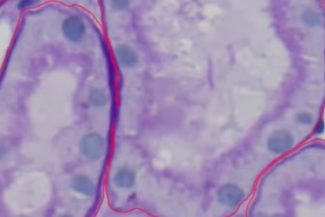


First Model for Glomerulus
PAS_008.czi Szene 1
Wie Sie am unteren Rand sehen können, zeigen die Bilder die Qualität der KI-Annotationen.
this image shows tubulus and PTC and how they connected



Key Medical Insights on Fabhalta® (Iptacopan) for Primary IgA Nephropathy Treatment
Wichtige medizinische Informationen:
Ergebnisse klinischer Studien: Fabhalta zeigte in der Phase-III-Studie APPLAUSE-IgAN eine signifikante Reduktion der Proteinurie, mit einer Reduktion um 44% gegenüber dem Ausgangswert nach 9 Monaten im Vergleich zu einer Reduktion von 9% in der Placebogruppe. Dies entspricht einer klinisch relevanten Reduktion der Proteinurie um 38% im Vergleich zum Placebo.
Wirkmechanismus: Fabhalta ist ein Inhibitor des alternativen Komplementwegs, der eine kritische Rolle bei der Entwicklung und Progression von IgAN spielen soll. Durch die gezielte Blockade dieses Weges hilft Fabhalta, die Entzündung und die nachfolgende Nierenschädigung zu reduzieren, die zu Proteinurie führen.
Sicherheitsprofil: Das Sicherheitsprofil von Fabhalta ist konsistent mit früheren Studien, wobei die häufigsten Nebenwirkungen obere Atemwegsinfektionen, Lipidstörungen und Bauchschmerzen umfassen. Schwerwiegende Infektionen durch Kapsel-bildende Bakterien stellen ein erhebliches Risiko dar, was spezifische Impfungen vor der Behandlung und eine sorgfältige Überwachung während der Therapie erforderlich macht.
Indikation: Fabhalta ist für Erwachsene mit primärer IgAN zugelassen, die ein Verhältnis von Urinprotein zu Kreatinin (UPCR) von ≥1,5 g/g aufweisen, was auf ein höheres Risiko für eine schnelle Krankheitsprogression hinweist.
Fortlaufende Zulassung: Die fortlaufende Zulassung von Fabhalta hängt von der Verifizierung des klinischen Nutzens durch laufende Studien ab, insbesondere in Bezug auf seine Wirkung auf die Verlangsamung des Nierenfunktionsverlusts, wobei wichtige Daten bis 2025 erwartet werden.
Weitere medizinische Überlegungen: Patienten, die Fabhalta einnehmen, müssen sich aufgrund des erhöhten Risikos schwerwiegender Infektionen gegen bestimmte Bakterien impfen lassen. Eine regelmäßige Überwachung der Cholesterin- und Triglyceridwerte ist ebenfalls erforderlich.
Zusätzliche Forschung: Fabhalta wird auch für andere seltene Nierenerkrankungen wie C3-Glomerulopathie, atypisches hämolytisch-urämisches Syndrom und Lupusnephritis untersucht.